

Authors:
RK Neelakandan - Health Quality and Safety Engineering Lead
Bhavana Bhinder - Google Cloud Office of CISO HCLS Europe Lead
Hugo Selbie - Google Cloud AI Incubation Engineer
The life sciences and medtech industries are on the cusp of a technological revolution, with Artificial Intelligence (AI) agents and agentic frameworks poised to reshape everything from drug discovery to regulatory affairs. These sophisticated AI systems can automate complex workflows, analyze vast datasets, and even assist in clinical decision-making. However, in a sector where patient safety and data integrity are paramount, robust evaluation methodologies are critical for building user trust in these agentic systems.
For Google Cloud customers in these regulated industries, the question is not just how to build and deploy AI agents, but how to demonstrate those agents consistently meet a robust set of security, quality and performance-based metrics. This involves repeatable testing and evaluating agentic capabilities in a way that is compliant, transparent, and trustworthy, with a methodology that can be explained and repeated. This blog post will provide a practical guide to evaluating AI agents in the context of life sciences and medtech, and how to align these evaluations with stringent regulatory requirements.
The Challenge: A New Paradigm for Trust and Validation
For decades, software validation has been built on a foundation of predictability and locked-down algorithms. You test the code, you validate its output, and you ship a system that performs its function identically every time. AI agents shatter this mold. Their probabilistic response means models can reason, adapt, and evolve—the very characteristics that challenge the traditional framework for ensuring safety and efficacy.
This dynamism creates a new and urgent imperative. The EMA and FDA in January 2026, released guiding principles of good AI practice in drug development lifecycles to support safe, responsible and harmonised use of AI. Global regulators are no longer just asking, "Does your software work?" The new, more critical set of questions focus on: "Can you prove AI-based tooling will continue to respond safely, effectively and predictably over a range of inputs as varied as human conversation?” and “How are you monitoring drifts, detecting and responding to variances in pre-defined thresholds"? Validating qualitative conversational responses and agentic interactions demands a new kind of evidence: proof of transparent reasoning, robust risk management, and a quality process designed for intelligent, adaptive technology. Failing to provide this evidence doesn't just risk a delayed product launch—it undermines the trust that is the bedrock of the entire industry.
A Multi-faceted Approach to AI Agent Evaluation
A robust and methodical evaluation framework for AI agents in life sciences and medtech should be multi-faceted, encompassing not just the final output of the agent but also its internal reasoning and decision-making processes. The pillars of such a framework should include strategic foundation, technical evaluation, regulatory imperatives and outcomes linked back to the strategy. These pillars are to be thought of as guides that an agentic evaluation strategy should encompass, modified appropriately for the Standard Operating Procedures, regulatory requirements and standards, and overall goal.
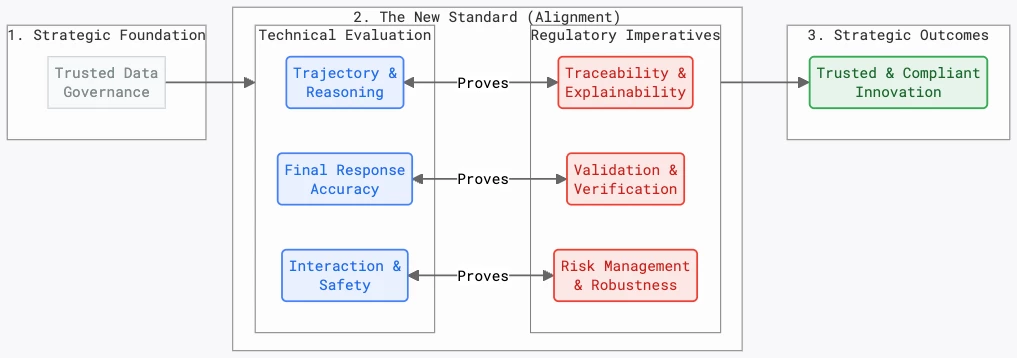
1. Trajectory Evaluation: Understanding the "How"
For regulators and internal quality teams, understanding how an AI agent arrives at a decision is just as important as the decision itself. This also critically supports foundational principles embedded in ALCOA++, GxP such as audit and traceability, transparency and explainability. Trajectory evaluation involves assessing the sequence of actions, or "tool calls," that an agent takes to complete a task. It focuses on the agent's process for making decisions. Key metrics to consider include:
- Exact Match: Does the agent's sequence of actions perfectly match a predefined, "golden" trajectory?
- In-order Match: Does the agent perform all the necessary actions in the correct order, even if it takes additional, non-essential steps?
- Any Order Match: The sequence of the necessary actions does not matter; this metric examines if all the necessary actions were performed.
- Precision: How accurate are the agent's actions? Using the reference trajectory as a baseline, the metric examines the precision of the predicted trajectory.
- Recall: Does the agent miss any crucial actions? This can be measured through the agent's ability to capture all necessary actions through a proportion of actions in the reference trajectory that are also in the predicted trajectory.
2. Final Response Evaluation: Assessing the "What"
While the trajectory is crucial, the final output of the agent must also be rigorously evaluated. Defining the evaluation data set to assess the agent is critical. This goes beyond simple accuracy and includes:
- Factual Correctness and Groundedness: Is the agent's output factually accurate and grounded in the provided source data, avoiding "hallucinations"?
- Task Completion: Did the agent successfully complete the entire task it was assigned?
- Adherence to Constraints: Did the agent's output adhere to all predefined constraints, such as regulatory guidelines or internal quality procedures?
3. Full Interaction Assessment
There are times when looking at the final response and the trajectory of the agent obfuscates the true nature of the agent quality. For instance, how do you measure the quality of a conversation? How would that measurement change if you are measuring the quality of a conversation that has an output tied to a patient safety process such as an adverse drug reaction? If a user spends a long time with an agent getting supplemental data, is that a bad interaction? Or an interaction that produces a higher quality output?
- Develop rubrics based on critical user journeys to define your desired interaction parameters of your agent.
- Rubric based metrics leverage LLM within workflows to assess the quality of a model's response. This makes them highly adept for Quality, Safety and Methodology-orientated tasks.
4. Human-in-the-Loop
For many of the nuanced and subjective aspects of AI agent performance, human evaluation remains the gold standard. Ultimately, these automated and AI-assisted methods are designed to augment and provide robust evidence for the final review and approval by qualified human experts. This can be complemented by using another large language model (LLM) as a "judge" to evaluate the agent's output against a predefined rubric. Depending on the business workflow, risk management principles and regulatory considerations, there are different approaches to configure. One approach commonly explored is having humans provide the initial subjective ratings of the AI agent that would then be codified into LLM-as-Judge responses for more scalable and automated assessments. Further configurations of the LLM as a judge model can be improved for quality, including system instructions and reducing judge model bias during evaluation. This approach can be particularly useful for assessing qualities like:
- Clarity and Coherence: Is the agent's output clear, concise, and easy to understand?
- Quality of response: How successful was the agent interaction?
- Safety and Bias: Does the agent's output avoid harmful, biased, or inappropriate content?
Aligning Evaluation with Regulatory Requirements
To bridge the gap between technical evaluation and regulatory submission, it's helpful to map these evaluation methods directly to the core requirements of bodies like the FDA and EU authorities. The following table provides a clear link between regulatory needs, evaluation techniques, and the tools available on Google Cloud.
| Regulatory Requirement | Regulatory Question to Address | Evaluation Method |
|
|---|---|---|---|
| Traceability & Explainability | Can you demonstrate how the agent reached its conclusion? Is the reasoning process transparent and auditable? | Trajectory Evaluation | Gen AI Evaluation Service on Vertex AI (using trajectory_exact_match, precision, and recall metrics), Vertex AI Experiments (for logging and visualizing execution traces) |
| Validation & Verification | How do you prove the agent's output is accurate, reliable, and performs its intended function correctly? | Final Response Evaluation | Gen AI Evaluation Service on Vertex AI (using metrics like ROUGE, BLEU, and custom computation-based metrics for correctness) |
| Risk Management & Safety | How do you ensure the agent is robust, safe for its intended use, and free from harmful bias? | Adversarial Testing, LLM-as-a-Judge, Human-in-the-Loop | Gen AI Evaluation Service on Vertex AI (using model-based metrics for safety, bias, and adherence to rubrics), Data Labeling services |
| Quality Management & Documentation | Do you have a documented, repeatable process for testing and ensuring quality throughout the agent's lifecycle? | Continuous Evaluation & Monitoring | Vertex AI Experiments (to log, track, and compare evaluation runs), Cloud Build (to automate evaluation in CI/CD pipelines) |
| Data Integrity & Governance | How do you ensure the data used to train and evaluate the agent is high-quality, secure, and managed appropriately? How to demonstrate adherence to ALCOA++ principles? | Robust Data Governance Framework | Google Cloud Dataplex, Data Catalog, BigQuery (for data quality checks, lineage, and access controls) |
Leveraging Google Cloud for Compliant AI Agent Evaluation
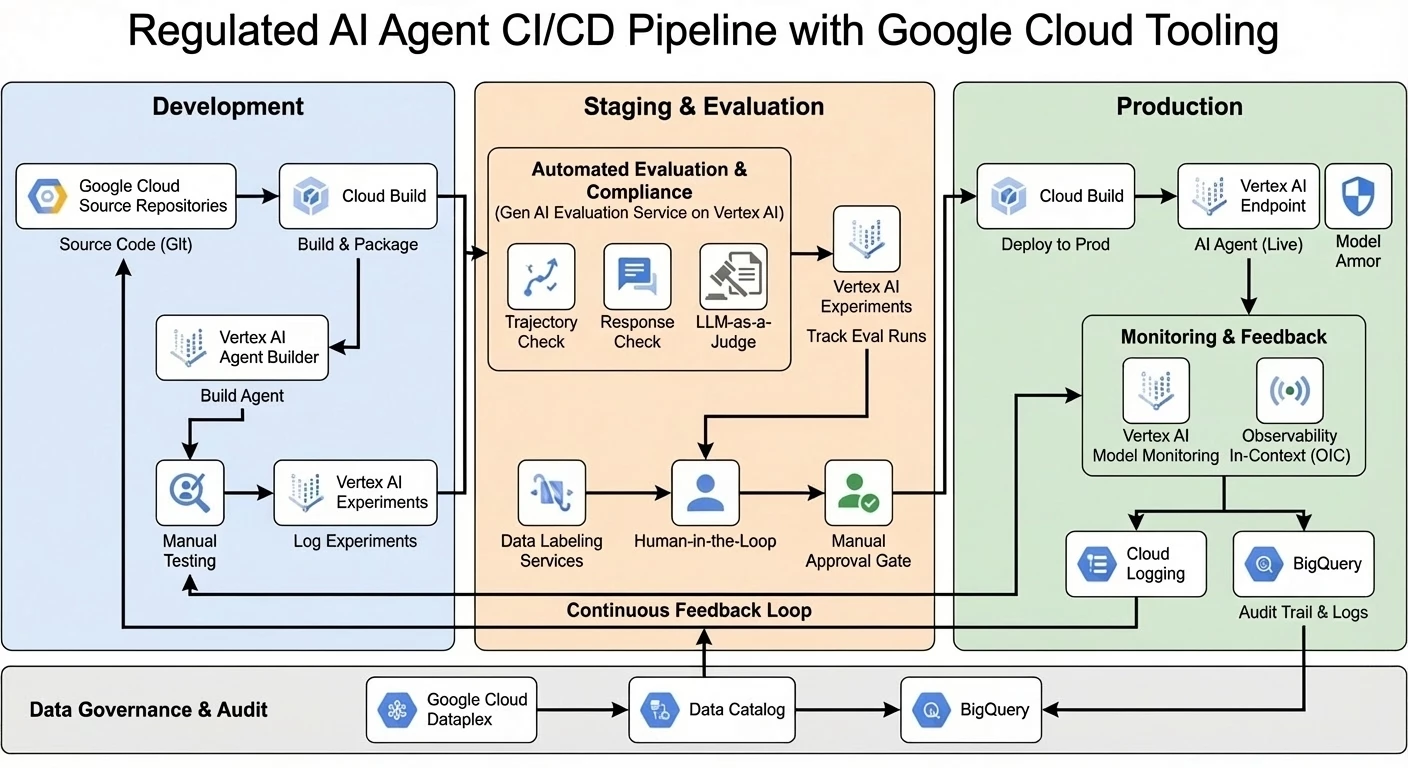
As outlined in the table, Google Cloud provides a suite of tools that can help life sciences and medtech companies build, deploy, and evaluate AI agents in a compliant and scalable manner. The reference architecture below illustrates how these components integrate to create a continuous, compliant feedback loop:
- Vertex AI Agent Builder: This platform provides the tools to create enterprise-ready generative AI experiences, from codeless conversational agents to complex multi-agent systems.
- Gen AI Evaluation Service on Vertex AI: This service is central to a compliant strategy, allowing you to rigorously assess your AI agents using a powerful set of evaluation metrics for both trajectory and final response. It supports both pre-built and custom metrics, enabling you to tailor your evaluations to your specific needs. The service also integrates with Vertex AI Experiments, allowing you to track and compare evaluation results over time.
- Agent Operational Governance: True compliance extends beyond initial testing; it requires a robust GenAIOps strategy to bridge the 'Day 2' gap between lab evaluation and real-world production. Google Cloud enables this through Vertex AI Agent Builder's integrated tracing, which allows developers to analyze complex agentic workflows using session-based and span-based views to pinpoint errors or latency. To ensure safety remains robust, Model Armor provides a real-time defense layer, inspecting inputs and outputs for risks like prompt injection and sensitive data leakage before they reach the agent or user. By integrating these operational insights with a continuous feedback loop, organizations can transform production data into quality improvements, ensuring agents remain secure, effective, and compliant at scale.
From Evaluation to Innovation: Your Path Forward
The integration of AI agents into the life sciences and medtech industries holds immense promise, but it also presents new challenges. By adopting a comprehensive and risk-based approach to AI evaluation, organizations can not only ensure the safety and effectiveness of their AI systems but also build trust with regulators and patients.
We encourage you to:
- Start with a Data Governance Assessment: Before deploying AI agents, conduct a thorough assessment of your data governance capabilities.
- Develop a Multi-faceted Evaluation Framework: This should be rooted in your critical user journeys that define high level success metrics for your agent. Implement a robust evaluation framework that assesses the trajectory, the final response, and the overall interaction of a user with your AI agents. This can be rapidly synthesized using agent simulation.
- Leverage Google Cloud's AI Tools: Explore how Vertex AI Agent Builder and the Vertex AI Evaluation Service can help you build, deploy, and evaluate your AI agents in a compliant and scalable manner.
By taking a proactive and strategic approach to AI evaluation, you can unlock the full potential of AI to drive innovation and improve patient outcomes in the life sciences and medtech industries.
Ready to build a solution for your life sciences needs? Explore our Life Sciences solutions page or contact our sales team to get started.