

Overview
Welcome back to our series on Actionable Threat Hunting with Google Threat Intelligence! This time, we're going to talk about a huge phishing scam that's just happened in the last few months. It's connected to Booking, which is one of the most popular websites for booking hotels.
Our main goal here is to show you how just one email we got helped us figure out how big this scam really was. We also found some interesting files that seem connected to Telegram messages the threat actors used. And don't worry, we'll share some of our code from Google Colab so you can try this yourself!
One clever thing about this scam is that the threat actors sent messages directly to victims through Booking's official website. They even used the message chats from bookings people had already made. This strongly suggests that the threat actors were somehow able to access this information through a method that is currently unknown.
‘Your reservation is at risk’
If you've recently received an email that appears to be from Booking.com, or even a message in the message thread of the Booking application for a reservation you had saying “your reservation is at risk”, don't worry, you're not alone.
For several weeks now, several users have reported a massive Booking phishing campaign where the actors behind the phishing sites are attempting to steal information such as credit cards. Pictured in Figure 1 is an example of a message sent through the Booking chat, using a real reservation thread.
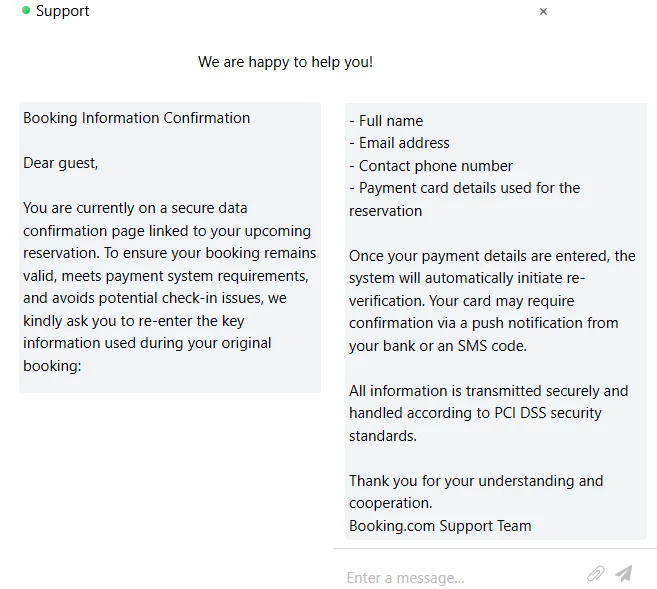
Figure 1: Example of message discovered in a phishing website related to booking.com
According to our analysis, the phishing message is sent using two different ways:
- Through the Booking.com website or mobile application, within the conversation thread with the hotel reservation.
- Through email from a legitimate Booking message.
For example, if you have a reservation at a hotel in Los Angeles made via Booking, the attackers will send you a message in that reservation's chat, stating that your booking is at risk and you must update your card details, otherwise it will be canceled.
Due to Booking.com's functionality, all messages sent via chat are also delivered to the user by email, which means the user receives the same message twice through two different channels.
In this campaign, the message the user receives contains a supposed URL that they must click to enter their card details and prevent their reservation from being canceled. Based on our observations, these URLs serve only as redirectors to the sites that actually host the fraudulent content.
Therefore, the actors registered Tier 1 domains that simply act as redirectors to the Tier 2 domains. The Tier 2 domains contain the content for stealing the victims' credit card details. Additionally, these domains were registered with names similar to "Booking" to make the user think it is the legitimate domain.

Figure 2: How this phishing is usually distributed
Discovering Tier 1 infra
The email we received had a domain setup that looked like [hotel_name].[3_letters]-[2_letters].com (for example: hostelmandarinkauxeh.eto-la[.]com). What's important here is that the first part of this domain name was actually the name of a real hotel from a current booking.
After you clicked the link from the Booking chat, it redirects you to a different URL. This new domain name tried to look like a real Booking domain, and its name often looked like booking.confirmation-id[5_numbers].com.
Knowing how redirects work, and the patterns of both domains, we can make different searches to help us find possible URLs related to the campaign.
The first query is to find Tier 1 URLs that redirect to Tier 2 URLs. To do this, we want to avoid getting results that are Tier 2 URLs. We can use the redirects_to modifier to set the pattern found in the Tier 2 URLs, which is the typical behavior. We will also use the hostname modifier to only show results for URLs that might be Tier 1.
entity:url redirects_to:"https://booking.confirmation-*" and not
hostname:"booking.confirmation-"
The results we expect from this search are URLs related to Tier 1 domains. Some example URLs we find will match the patterns we described earlier:

With the results we have, we now want to find certain patterns that all these URLs share. This way, we can widen our search to find new possible URLs related to both Tier 1 and Tier 2 infra. Let’s focus on the HTML information from these URLs obtained in the first query.
For the following code examples we are going to use vt-py, we recommend you read the documentation and the examples that we have available in our GitHub repository to get familiar. The next code snippet is the base to build the rest of the code snippets that we have to obtain different kinds of data.
| | DISCLAIMER: Please note that this code is for educational purposes only. It is not intended to be run directly in production. This is provided on a best effort basis. Please make sure the code you run does what you expect it to do. |
# Base code
# Before running the code, make sure you have enough quota to do so. This query can consume a lot of quota.
import vt
cli = vt.Client(getpass.getpass('Introduce your VirusTotal API key: '))
query = "entity:url redirects_to:\"https://booking.confirmation-*\" and not hostname:\"booking.confirmation-\"" # @param {type: "string"}
# Look for the samples
query_results_t1 = []
async for itemobj in cli.iterator('/intelligence/search',params={'query': "%s"%(query)},limit=0): # Set the limit you want
query_results_t1.append(itemobj.to_dict())
all_results_t1 = list(json.loads(json.dumps(query_results_t1, default=lambda o: getattr(o, '__dict__', str(o)))))
From the initial query that we ran, let’s get the HTML titles and group them to identify the most observed. We can achieve this by running the following snippet in our Google Colab.
# Get URL Titles
df = pd.DataFrame(columns=['title', 'url'])
for item in all_results_t1:
# Get the 'attributes' dictionary from the current item, defaulting to an empty dictionary if not present
attributes = item.get('attributes', {})
# Get the 'title' and 'url' values from the attributes dictionary
title = attributes.get('title')
url = attributes.get('url')
# Check if both title and url are present (not None or empty)
if title and url:
# If both are present, create a new DataFrame with the title and url
# and concatenate it to the main DataFrame. ignore_index=True resets the index.
df = pd.concat([df, pd.DataFrame({'title': [title], 'url': [url]})], ignore_index=True)
# Group by title and count the number of URLs
title_counts = df.groupby('title')['url'].count().reset_index(name='url_count')
# Sort by url_count in descending order
title_counts = title_counts.sort_values(by='url_count', ascending=False).reset_index(drop=True)
# Display the resulting DataFrame
display(title_counts)
Running the last code snippet, the TOP 5 titles we obtained were the following:
| Title | Count |
| One moment... | 779 |
| One moment… | 67 |
| AD not found (captcha2) | 46 |
| Suspected phishing site | Cloudflare | 5 |
| booking.confirmation-id83974.com | 521: Web se... | 5 |
The first two results might look the same, but they are not. The difference is the dots used after One moment. In this case, it seems the first three results are the most common, so we can save this information to build a search later. Please note that these values can be used with the title modifier for URLs.
Another interesting piece of information that could help find new URLs is the <meta> tags from the URLs we've identified. To do this, we will run a search like before, but this time, instead of titles, we will look at the values of any <meta> tag. These values can be used with the meta modifier.
# Get meta values
from collections import Counter
all_meta_values = []
# Iterate through each item in dsaaaa (assuming this contains the relevant data)
for item in all_results_t1:
attributes = item.get('attributes', {})
html_meta = attributes.get('html_meta', {})
# Iterate through the values of the html_meta dictionary
for meta_values_list in html_meta.values():
# Extend the all_meta_values list with the items from the current list
all_meta_values.extend(meta_values_list)
# Count the occurrences of each unique meta value
meta_value_counts = Counter(all_meta_values)
# Convert the counts to a pandas DataFrame
df_meta_counts = pd.DataFrame(list(meta_value_counts.items()), columns=['Meta Value', 'Count'])
# Sort by count in descending order
df_meta_counts = df_meta_counts.sort_values(by='Count', ascending=False).reset_index(drop=True)
# Display the resulting DataFrame
display(df_meta_counts)
The results we got from the <meta> tags were very interesting, and there were over 750 possible results. First, we found many meta values that actually were URLs storing images. Some of these images were icons used on fake websites, and others were from hotels hosted in a legitimate Booking domain.
- URL identified in the <meta> tags 126 times: hxxps://ltdfoto[.]ru/images/2025/06/04/photo_2025-06-02_11-23-22.md.jpg
- URL identified in the <meta> tags 14 times: hxxps://cf.bstatic[.]com/xdata/images/hotel/max300/619949340.jpg?k=971fb717a1df5b8d7ae0b077411493921f7f041a8992a9deb4d11b8aef870571&o=
Bstatic.com is a legitimate domain owned by Booking. Multiple images hosted in that domain were discovered in the <meta> tags of the phishing websites.
We also found many strings in the <meta> tag values that started with Booking - [hotel_name]. This finding is interesting because there were up to 400 possible results that started this way. Some examples were the following:
| Meta string | Count |
| Booking - HEIMALEIGA - Your Icelandic home awa... | 24 |
| Booking - Grand Hotel Duomo | 9 |
| Booking - FOUND Hotel Carlton Nob Hill | 7 |
| Booking - La Castellana | 7 |
| Booking - Payment verification | 7 |
| … | … 1 |
| Booking - Hotel Hagemann | 1 |
| Booking - Tahiti Airport Motel | 1 |
| Booking - Hotel Aldea Berlin | 1 |
| Booking - Fasthôtel Clermont-Ferrand Gerzat | 1 |
Basically, with these results, we can now add more filters to our first search or even create a new one. The following query can help us to expand the results and get new URLs that could be related to some Booking campaigns, even before this one.
entity:url fs:2024-09-01+ (title:"One moment" or title:"AD not found
(captcha2)") and (meta:"Booking -" or
meta:"https://ltdfoto.ru/images/2025/06/04/photo_2025-06-02_11-23-22.md.jpg" or
meta:"https://cf.bstatic.com/xdata/images/hotel/") and not
(hostname:"booking.confirmation-" or hostname:"booking.com")
Figure 4: Ways to do hunting in the Tier 1 infra (download format)
Discovering Tier 2 infra
We have enough information to also find Tier 2 infrastructure set up by the actors. The first thing we will do is look for domains that match the patterns we found earlier, with the following search. The next search gives us over 100 recently registered domain results.
entity:domain domain_regex:"^booking\.confirmation-id[0-9]{5}\.com$"
Figure 5: Tier 2 domains matching the query regex
The next step is to find URLs that have that pattern in their hostname. One of the best queries that we can run in this case is the following.
entity:url hostname:"booking.confirmation-id*"Around 1,500 URLs match the hostname criteria, and all of them are related to Booking campaigns. In fact, the oldest URL was uploaded to the platform in November 2023.
To follow the same idea we used with the Tier 1 URLs, it would now be good to look for titles and patterns in the <meta> tags for all these new URLs discovered with the last query. This could help us find new possible phishing sites. For the titles we obtained the following results.
| Title | count |
|---|---|
| AD not found (captcha2) | 492 |
| One moment... | 300 |
| Booking.com | Official website | Best hotels and accommodation | 43 |
| One moment… | 33 |
| 403 Forbidden | 23 |
| Booking.com | Official site | The best hotels & accommodation | 17 |
| Suspected phishing site | Cloudflare | 16 |
| 404 Not Found | 16 |
| Just a moment... | 14 |
| Booking.com | Official site | The best hotels, flights, car rentals & accommodations | 8 |
Strings like One moment or AD not found (captcha2) were seen before in the Tier 1 infrastructure. However, in this case, we also see another title pattern that could be interesting to find other URLs, like Booking.com | Official.
For patterns found in the <meta> tags, we saw similar results. However, there are also values that start with Booking.com followed by the hotel's name, similar to the pattern identified in infra Tier 1 Booking - followed by the hotel's name.
| Meta String | Count |
| https[:]//ltdfoto[.]ru/images/2025/06/04/photo_2025-06-02_11-23-22.md.jpg | 68 |
| light dark | 40 |
| Booking.com | 34 |
| company | 34 |
| https[:]//www.booking[.]com | 26 |
| Booking.com Hotel Reservations | 16 |
| com.booking | 16 |
| Booking.com: The largest selection of hotels, homes, and vacation rentals | 16 |
| @bookingcom | 16 |
| Booking - Wind Hotel | 3 |
| Booking: Barcelona City North Hostal | 2 |
Based on the results, if we want to create a new query and make sure we only get URLs related to the Tier 2 infrastructure, the next search will definitely give us that information.
entity:url (title:"One moment" or title:"AD not found (captcha2)" or
title:"Booking.com | Official") and (meta:"Booking -" or
meta:"https://ltdfoto.ru/images/2025/06/04/photo_2025-06-02_11-23-22.md.jpg" or
meta:"https://cf.bstatic.com/xdata/images/hotel/") and
hostname:"booking.confirmation-*"
Figure 6: Tier 2 URLs matching the query
With this, we'll now have access to URLs that have been distributed by the threat actors for Tier 2. Next, we will put together all the URLs from both Tiers to better understand this campaign and get more details.

Figure 7: Ways to do hunting in the Tier 2 infra (download format)
We've uncovered the intricate layers of this massive phishing operation. Now, Part 2 reveals how we leveraged these discoveries to track the threat actors, uncover their tools, and empower actionable defenses.