
Author:
Amitabha Roy, Software Engineer • Engineering - SCC Suite
Google Cloud Fraud Defense (formerly reCAPTCHA) has evolved significantly to enter the AI era. In addition to supporting agents as first class users in the browser we have extensively revamped our detection stack to leverage the most advanced predictive machine learning available today to truly model user and bot behavior to adapt continuously to new bots and threat vectors.
Jettisoning the CAPTCHA
Contrary to its nomenclature, Google Cloud Fraud Defense (simply Fraud Defense in this blog) has moved beyond traditional CAPTCHAs. As computer vision advancements allow adversaries to easily identify traffic lights, we have shifted our focus. By leveraging a predictive AI stack, we utilize behavioral signals to calculate an abuse score that quantifies suspicion without interrupting genuine users. At the heart of this "verdict" is an orchestration of an entire ensemble of machine learning models that process signals within tight latency bounds to return an inferred score. Read on to explore the mechanics behind this process.
The Ensemble
The most important aspect of Fraud Defense’s AI generated verdict is that it does not use a single model. Rather, it uses an entire ensemble of models including transformers, deep neural networks, trees and even logistic regression all orchestrated with Google’s MLOPs infrastructure (think Vertex AI) to return an inferred verdict score on time.
The key idea of ensembles is well known in the machine learning community - each model learns to specialize on a particular threat vector or type of bot. For example, some of our models are specialized towards measuring the reputation of end point identifiers visible to us, other models focus on the interaction of users with webpages protected by Fraud Defense. Yet other models examine characteristics of the end point device connecting to the webpage or using the app. Our ensemble models are also pipelined with models consuming the output of other models and refining their opinions. This pipelining is crucial for interpretability as we explain later.
We continuously hot swap and refresh models in our ensemble to keep up with our adversaries who are continuously evolving.
Fast vs Slow
Fraud Defense's ensemble includes both "fast" and "slow" models. This distinction allows us to model different aspects of user activity. Our fast models focus on immediate interaction signals and reputation for the entity accessing the website protected by Fraud Defense. They process data within tight latency bounds to ensure a quick verdict score leveraging Google’s vast distributed model serving infrastructure, ensuring our models are always close to the end point serving your reload or create assessment requests.
Our slower, more sophisticated models—like a transformer—analyze long-term reputation and comprehensive user behavior including interaction over multiple sessions to determine if an entity is a genuine human or a pretender bot. Since models that analyze long-term reputation can be computationally intensive (compare our verdict latency to your favorite LLM!), we use a technique called distillation (a well-known concept in the ML community) to transfer the high-quality labels from these advanced models to cheaper models in our ensemble that can then run online to return verdicts in time.
Notably, the slower models are able to use and denoise user annotations. This is why we request customers to send annotations of sessions to us when possible. Customer opinions about the nature and origin of a session are valuable to mapping out the threat landscape and especially for identifying new threats. Customers are often able to access secondary sources of reputation for a session for example via a triggered two factor authentication. Of course these are best effort opinions (which is why customers ultimately depend on the Fraud Defense verdict) and are often noisy. Our slow models include a fair amount of machinery for denoising and are able to extract signals from annotations without depending on them as absolute labels.
Interpretability
Interpretability is a first class requirement for models in Fraud Defense and on the engineers who design them. As a Fraud Defense customer you already know this! The extended reasons we return in addition to our score is a concrete piece of interpretability output we expose to customers as well use ourselves for debugging and handling escalations. Part of the secret sauce in being interpretable is carefully selecting models at the top of the pipeline. The models closest to the score are linear models that are easy to interpret with their weights often directly translating into activation of extended reasons.
Some examples of extended reasons with fairly self-explanatory names (by choice) are “Low reputation client”, “Suspicious browsing behavior” and “Low integrity app”. The reader might find it useful to compare the three corresponding examples highlighted in the section on model ensembles - illustrating the mapping from models to extended reasons to expose observability from our machine learning stack all the way to the customer.
Calibration
We have already mentioned Fraud Defense’s models are refreshed continuously, at times within weeks. A somewhat remarkable aspect of our MLOPs is that this is entirely invisible to our customers who often set thresholds on our scores to action on incoming web requests and depend on our score distributions staying stable even as we continuously update many models in our stack asynchronously. The way we achieve this is by introducing calibration into our score. This was driven by asks from our customers that made it clear to us that maintaining score stability is paramount and we have heard you!
As our detection capabilities improve, each new model successfully pushes sophisticated bots into lower score bands. As with any statistical technique there will be sessions that do not receive a score at either end of the scale. Customers who choose to act at thresholds in between, such as 0.3, expect to maintain consistent performance such as the same false positive rate. To enable this we include an online calibration layer after our ensemble to calibrate the score before returning it in the verdict.
This means customers do not need to change their fraud thresholds; instead, score distribution shifts on their dashboard will simply reflect better models and the changing threat landscape between bots and humans. For example if their website is attacked they will see a spike in sessions receiving lower scores and be assured that these additional sessions are bots and are not reflective of a change in the models in our stack. A typical way to look at calibration quality is with a calibration curve that plots scores (raw and calibrated) on the x-axis against label ratios on the y-axis. A chart (not real!) would look somewhat like this - with the calibrated score more closely following the diagonal.
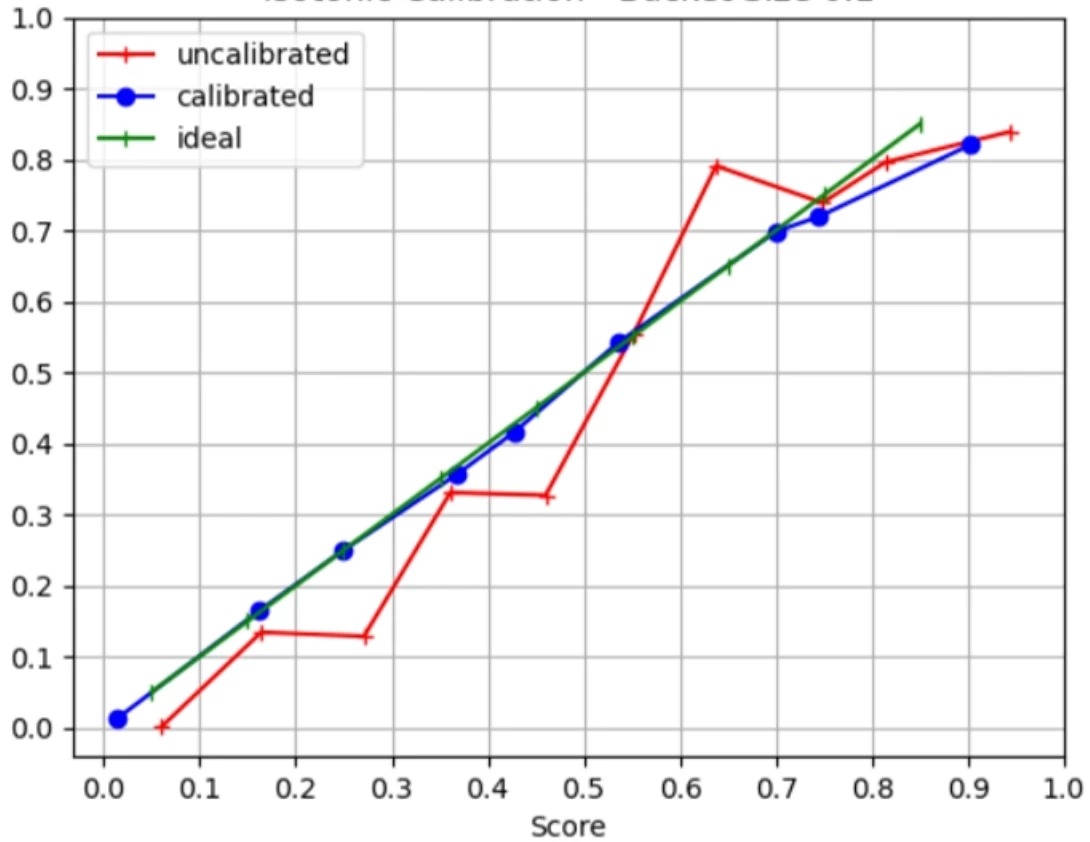
Many of Fraud Defense’s APIs already have a calibrated score and we are rolling out calibration for mobile scores with newer SDKs. This ensures you get the best possible metrics for your scores (we internally track area under the curve metrics continuously) while being able to count on the score distribution for routing and blocking decisions at your end.
Conclusion
Google Cloud Fraud Defense includes a highly sophisticated set of machine learning models that evolve continuously in response to threats on the internet. We strive to update our ensemble with newer techniques and algorithms as they become available - this burden on our engineers has been eased of late by making extensive use of agentic software development workflows. At the same time we are mindful of our customers who depend on the stability and quality of our score - we are reliable and available at internet scale!
