



This topic is a hearty one and will take a few blogs to cover in depth, so stick with me today as we cover the high level concepts and then come back for more detail, it’ll be worth it, I promise.
We’ve looked at using data tables for column matching, row matching, working with large data sets as well as writing to a data table from a search and a rule in Google Security Operations (SecOps). Today we are going to use data tables to extend the entity graph functionality in rules. When I say extend the entity graph, there are actually three different ways that data tables can work with the entity graph; as an override of the data in the entity graph, as an exclusion of what is in the entity graph and to append data table content to data from the entity graph.
Entity Graph
For those not familiar with the entity graph, let’s take a moment and provide a high level overview. The entity graph stores contextual data, including information about assets, users, groups, resources and IOCs in SecOps. This contextual data is stored as entities which can be searched and used in rules. Additionally, this data is also used to enrich UDM event data.
The entity graph is also a repository for derived data like prevalence, UEBA metrics and Google Threat Intelligence. In short, it is a powerful data repository that provides analysts with additional capabilities to identify suspicious activities.
That all being said, data is ingested into the entity graph using the same methods that UDM event data uses and parsers are built for these different data sets, so whether you are using Windows Active Directory, Workspace, CMDB or any other entity context this contextual data can be ingested.
In many cases, rules can be written using the enriched UDM event data. Sometimes, rules need to be written joining events to the entity graph and sometimes, we need some additional flexibility to leverage what we have in the entity graph but augment it in some way. This is where data tables come in.
When to use Data Tables with the Entity Graph
Before we start building rules that leverage data tables, we need to first ask ourselves if we need to utilize this functionality. The chart below provides a decision tree to assist us. Adding the entity graph to a rule adds complexity, not in a bad way, but it requires us to ensure the data is joined properly. Adding data tables to further extend our use case also adds complexity, but it also gives us more choices and capabilities than we had previously. Depending upon the situation, we need to use these tools to meet our detection requirements, but if we can address our detection needs without these more advanced techniques, then why use them and create additional complexity?
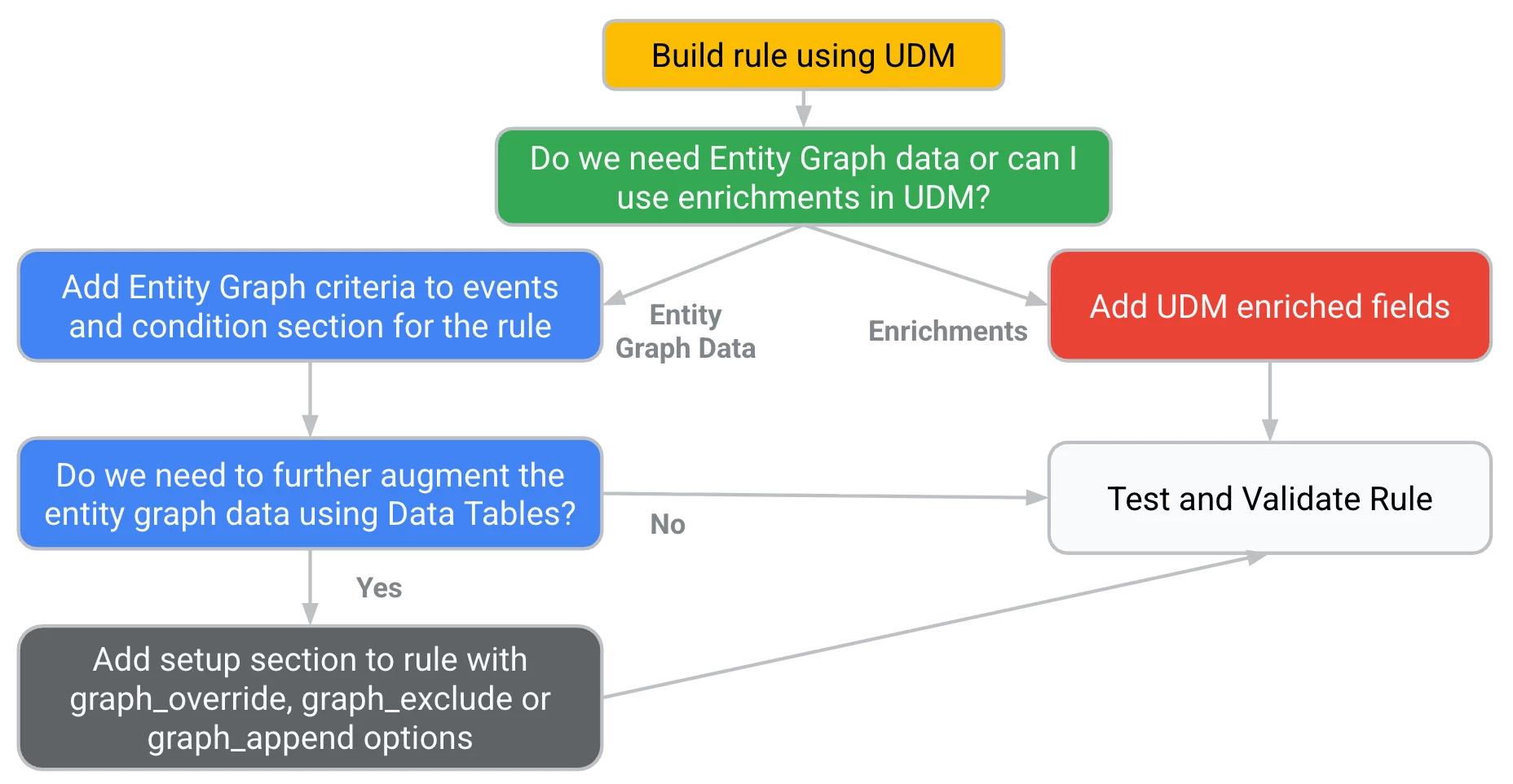
When building a rule, first determine if we need data from the entity graph. If we do, can we use fields that are enriched into the UDM event already? For instance, the department, user name, title, and other fields are already enriched and you might not need to use the entity graph.
If you do need data in the entity graph, that’s fine, we can use it to construct the rules. Taking this one step further, do we need to leverage data tables with the entity graph to build our rule? If so, we are going to add a new section to the rule with one of three graph command options and build from there.
Data Table Integration Options
To integrate data tables and the entity graph, a new construct is available for YARA-L rules called setup. The setup section is placed after the meta section and before the events section in a rule. There are three commands that can be used in this section; graph_override, graph_exclude and graph_append.
At a high level, what do these options mean? The graph_override option is designed to use the data within the data table instead of the data in the entity graph.
The graph_exclude option allows a detection engineer to take values that exist in the entity graph and if a match exists in the data table, the matched values would be excluded from the rule results.
Finally, graph_append takes the contents of the entity graph and appends values from the data table. With this option, think of the data table as an extension of the entity graph.
That is really just scratching the surface but hopefully provides a nice introduction. We will be going into greater detail on each one of these options and we will use them in rules to demonstrate how they could be used.
Building a Data Table for Entity Graph Integration
Before we can write rules using these options, we need to create data tables that can map to the entity graph. We’ve built data tables previously so we won’t be discussing the data loading process today. However, we will be taking a look at the mapping of the data table columns as this is different for entity graph integration.
Previously, we mapped the columns in a data table to a data type; string, regex, cidr, or number. To integrate data tables with the entity graph, at least one column must be mapped to a field in the entity graph. Do all fields need to be mapped to the entity graph? No, because not all the columns in the data table may exist in the entity graph.

Notice in the example above that two rows of drop downs are displayed above the table header columns. These rows can be toggled to display by clicking the check boxes under Edit Mode. One row contains data types. The second row contains drop-down menus for entity graph fields that the columns can be mapped to.
However, notice that when I click on the mapping dropdown, I get a tool tip that states that entity mapping isn’t available because a data type is assigned to the column. A column in a data table can be mapped either to a data type or an entity graph field, but not both.

To resolve this, change the data type to Unspecified and the drop down mapping will become available. Typing in a string like userid will reduce the field choices to just those that contain that value.
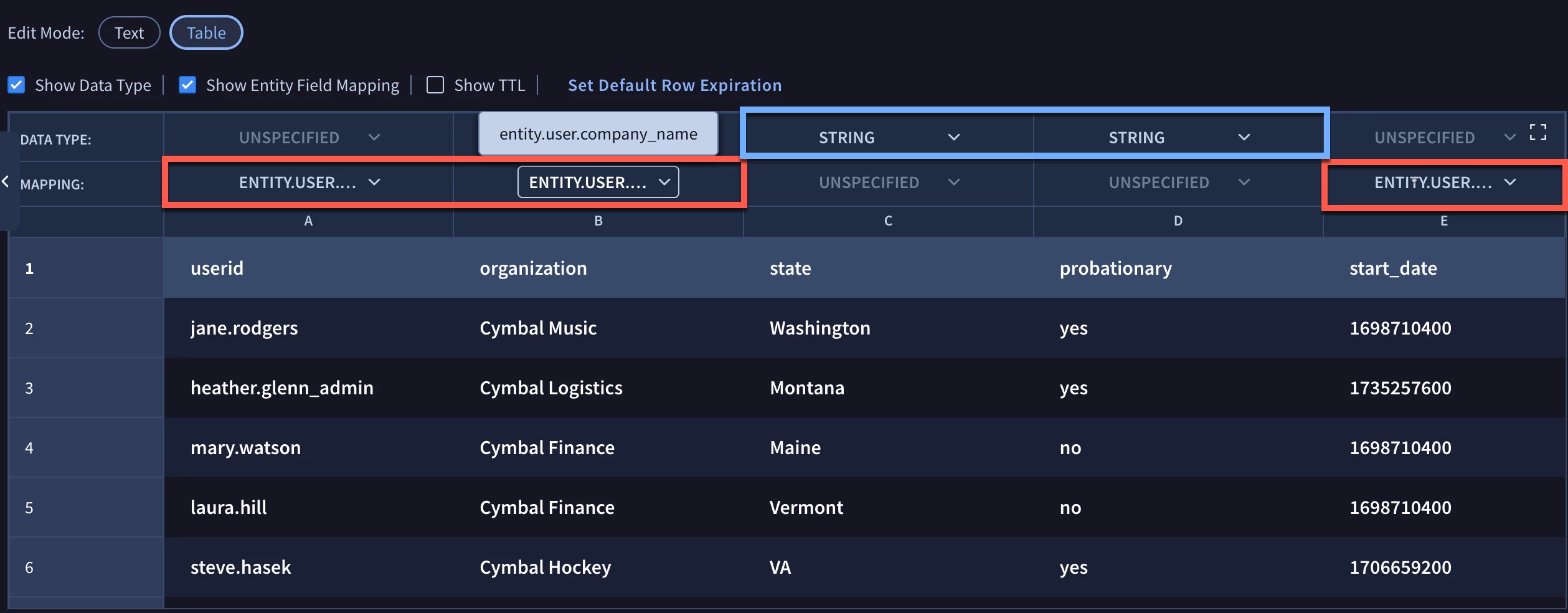
For our first example, we have mapped the userid column to the entity.user.userid field, organization to entity.user.company_name and start_date to the entity.user.hire_date.seconds. Two additional columns named state and probationary are mapped to string fields.
A few things to be mindful of as we start working with Entity Graph and Data Table integration:
- Don’t make rules more complex to use entity graph and data tables; these capabilities are designed to help you achieve a desired outcome
- Leverage data tables with the entity graph when you want to override the entity graph values, exclude entity graph values or append additional data to the entity graph
- Add a setup section to the YARA-L rule between the meta and events section
- Data table columns can be mapped to a data type or an entity graph field but not both
With a data table created, mapped and loaded, our next blog will dive into building rules with the entity graph and our data table using the graph_override command.
