

David French wrote about data tables earlier this year and I wanted to circle back and take a look at some additional capabilities of data tables that you may not be aware of. In this blog, we will walk through loading a large reference dataset and utilize it in a Google Security Operations (SecOps) rule.
The reference dataset we are going to work with today is the Cisco Umbrella Popularity List. This list contains the top one million queried domains based on passive DNS. The list itself is updated on a daily basis and is available in csv format, compressed into a zip file.
Loading a Large Reference Dataset via the API
David demonstrated in this blog how we can create a data table via the UI. While we could do that in this example, we can also programmatically create this data table AND load the data from csv at the same time. Here is the curl statement to perform these tasks:
curl --location -X POST \ 'https://us-chronicle.googleapis.com/upload/v1alpha/projects/<GCP_PROJECT_NUMBER>/locations/us/instances/<CUSTOMER_ID>/dataTables:bulkCreateDataTableAsync' \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "X-Return-Encrypted-Headers: all_response" \
-H "Content-Type: multipart/form-data" \
-F 'data_table={"data_table_id":"cisco_umbrella_pop_list", "data_table": {"name": "projects/<GCP_PROJECT_NUMBER>/locations/us/instances/<CUSTOMER_ID>/dataTables/cisco_umbrella_pop_list", "column_info": [{"column_index": 0, "original_column": "rank","column_type": 4}, {"column_index": 1, "original_column": "fqdn","column_type": 1}]}};type=application/json' \
-F "file=@top-1m.csv;type=application/octet-stream" \
--verbose -i \
-H "X-Goog-Upload-Protocol: multipart"
Let’s take a look at what we have here. We can start by specifying a URL that will depend on what region your Google SecOps instance resides in. We will also need to gather our GCP Project Number and Customer ID. These can easily be retrieved from the SIEM Settings - Profile page.
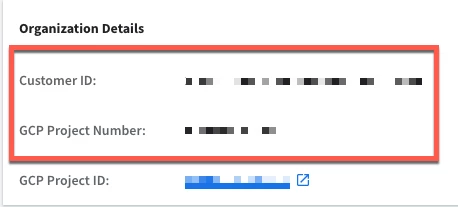
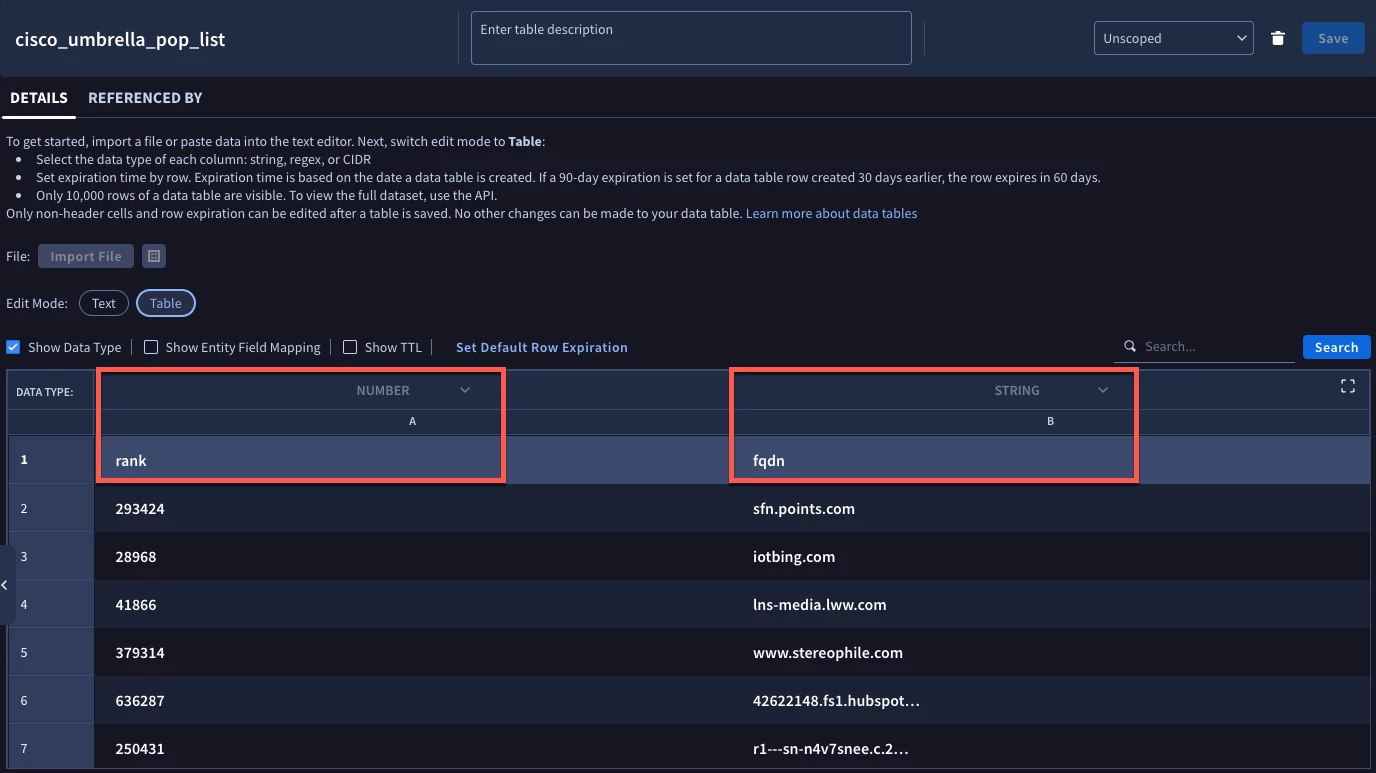
The next step is to name your data table. In my curl statement, I am using cisco_umbrella_pop_list as the name of the data table. After this, we need to identify the columns in the data table. This data set has two columns in it so it is very straightforward. We are going to name the first column rank and the second column fqdn, short for fully qualified domain name. Notice that column numbering starts at 0. Column_type is an enumerated value that defines the type of data being stored in the field. A column type of 1 denotes string and a column type of 4 denotes a number. Therefore the rank would have a column type of 4 and the fqdn has a column type of 1.
Finally, we are going to specify the name of the csv we are going to upload. In my case, I am executing the curl statement in the same directory where the csv resides.
Assuming we get a HTTP status code of 200, we can open the SecOps UI and take a look at our data table. Here we can see the data type for each column. Once we are satisfied that our data came in neatly, let’s head over and build a rule.
Using column and row matching in YARA-L Rules
Let’s start by creating a rule for our DNS queries. Detecting all DNS queries doesn’t seem like a great idea, but it is a good place to start as we refine our rule. In the events section, we are using the function net.ip_in_range_cidr to focus our rule on events that have a principal.ip that exists within the internal_ip_ranges data table and within the ip_block column. If we wanted to focus on DNS events that were not in those IP blocks, prepending the not operator to the function would do the trick. This column contains CIDR notation of IP ranges.
rule dns_queries {
meta:
author = "Google Cloud Security"
description = "Detect external DNS queries"
events:
$dns.metadata.event_type = "NETWORK_DNS"
net.ip_in_range_cidr($dns.principal.ip, %internal_ip_ranges.ip_block)
$dns.network.dns.questions.name != /lunarstiiiness\.com\.$/
$dns.network.dns.questions.name != /lunarstiiiness\.com$/
$dns.network.dns.questions.name != /\.internal$/
$dns.network.dns.questions.name != /\.local$/
$dns.network.dns.questions.name != /\.in-addr\.arpa$/
$dns.network.dns.questions.name != "*"
$dns.network.dns.questions.name = $domain
match:
$domain over 24h
condition:
$dns
}
We are also excluding a number of DNS queries that are internal and not interesting for the purpose of this exercise. Could we have used a data table to ignore these values? We certainly could have, particularly if we are using that logic in multiple rules or searches!
Aside from the filtering, we are aggregating the DNS queries over a 24 hour window. When we test our rule, we get hundreds of detections, which is fine, but not very actionable.
If we refine this rule using our Cisco Umbrella Popularity List, we could generate a set of detections where we have DNS queries that are not in this listing by adding one line to our rule.
rule dns_queries_not_top_1m {
meta:
author = "Google Cloud Security"
description = "Detect external DNS queries"
events:
$dns.metadata.event_type = "NETWORK_DNS"
net.ip_in_range_cidr($dns.principal.ip,%internal_ip_ranges.ip_block)
$dns.network.dns.questions.name != /lunarstiiiness\.com\.$/
$dns.network.dns.questions.name != /lunarstiiiness\.com$/
$dns.network.dns.questions.name != /\.internal$/
$dns.network.dns.questions.name != /\.local$/
$dns.network.dns.questions.name != /\.in-addr\.arpa$/
$dns.network.dns.questions.name != "*"
not $dns.network.dns.questions.name in %cisco_umbrella_pop_list.fqdn
$dns.network.dns.questions.name = $domain
match:
$domain over 24h
condition:
$dns
}
This line is in bold above. We are comparing the field the DNS query is in to the list. This is similar to a reference list except the syntax for the data table is the data table name followed by a period and the name of the column. In this case, we are just looking for a match in the column fqdn, so we can use keyword IN to denote we are performing a column match. Because we want to find those DNS queries that don’t match, we can prepend our statement with NOT.
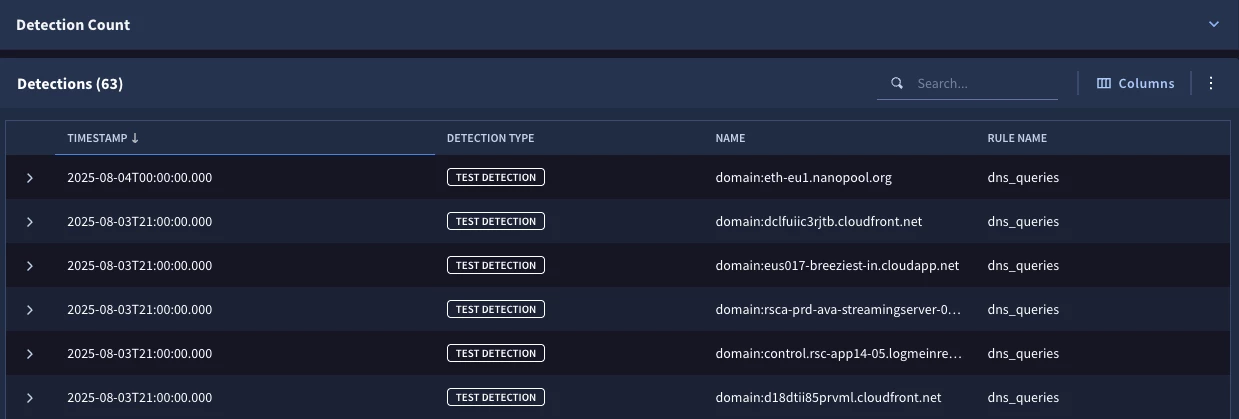
When we test our rule, we’ve gone from hundreds of DNS queries in our detection set to 63 that are not in the top one million DNS queries.
Let’s take a look at a related by slightly different use case and continue to use this data table. This time, let’s say we want to know when DNS queries are occurring and match domains in the listing. That alone would create numerous detections, but perhaps we want to focus on the lower ranked domains in the list of one million. In my example, I feel pretty good about the first 700,000 domains, but those from 700,001 to 1,000,000 are ones that I’d like to detect.
To do this, let’s start by making an adjustment to the statement that references our data table. We will start by removing NOT and we will swap the keyword IN for an equal sign. This is the first step in creating a row match between an event and a data table. Row matching will always start with a UDM field joining to at least one column in a data table. Column matching, which we looked at earlier, uses the IN keyword and independently assesses a column of values.
rule dns_queries_in_top_1m_over_700k {
meta:
author = "Google Cloud Security"
description = "Detect external DNS queries"
events:
$dns.metadata.event_type = "NETWORK_DNS"
net.ip_in_range_cidr($dns.principal.ip,%internal_ip_ranges.ip_block)
$dns.network.dns.questions.name != /lunarstiiiness\.com\.$/
$dns.network.dns.questions.name != /lunarstiiiness\.com$/
$dns.network.dns.questions.name != /\.internal$/
$dns.network.dns.questions.name != /\.local$/
$dns.network.dns.questions.name != /\.in-addr\.arpa$/
$dns.network.dns.questions.name != "*"
$dns.network.dns.questions.name = %cisco_umbrella_pop_list.fqdn
$dns.network.dns.questions.name = $domain
match:
$domain over 24h
outcome:
$rank = max(%cisco_umbrella_pop_list.rank)
$principal_hostname = array_distinct($dns.principal.hostname)
condition:
$dns and $rank > 700000
}
You might be thinking, why do I care about row versus column matching? Well, now that we have a row match in the events section, we can extract the rank from the data table and write it to an outcome variable which is what we have done in the outcome section. Notice we are using the aggregation function of max because rank is stored as a number.
From there, we can easily add a greater than statement to the condition section of the rule that states the rank must be greater than 700,000 for the rule to trigger.
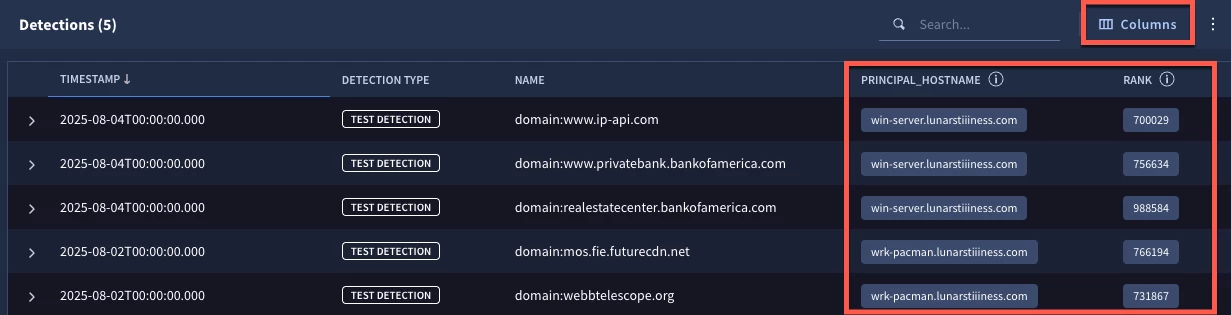
When we test our rule, we have five detection for domains in this outer range of the top one million domains. By clicking Columns, we can add our outcome variables of principal_hostname and rank to our output to validate the logic we created.
Today, we created and loaded a large reference dataset in a single step using a curl command and then used this large data set to create rules using column and row matching. When you are using these techniques, here are a few things to remember:
-
Make sure you think about the kind of data you will be loading into the table and set the data type (column_type in the API) accordingly
-
While you can use functions like cast.as_float or cast.as_string to manipulate data once it is the data table, it’s easier to make sure you select string or number correctly upfront as we did today
-
The keyword IN is used for column matching and is much like a reference list for those who have used it in the past
-
Equal sign will denote a row match and allow us to use additional columns of information that are associated with the value that is matched
-
If you want to use other values like the rank in your rule, output them in the outcome section of the rule
With that, we are going to wrap up. We will have more on data tables but hopefully this highlights how easy it is to load large reference datasets into Google SecOps and how data tables can provide both row and column matching to your detections!