


This installment of New to Google SecOps will look at a few functions that make it simpler to work with URLs and other fields where hostnames and domains may be lurking. Oftentimes, we are provided with a field that starts with http:// or a username and we need to extract the hostname or domain from it. While these values could be extracted with regex functions, some readers of this blog may look forward to that as much as a visit to the dentist. Hopefully after reading this blog, extracting domains and hostnames won’t feel like we are pulling teeth!
strings.extract_hostname and strings.extract_domain
I contemplated separating these two into their own sections, but as I thought it through, they are very complementary and when describing one, we often end up describing the other, so I’m going to discuss them together.
Let’s start with a look at a search. This example is pretty straightforward, we want all web traffic where the target URL starts with http://www.. This line of criteria uses the strings.to_lower function to ensure we return all events that start with this string, no matter if they are upper, lower or mixed case.
The strings.extract_hostname and strings.extract_domain functions both take a single argument and in the example, we are outputting the results to placeholder variables. Let’s use these variables in the match section and output the target.url as well in our search results.
metadata.event_type = "NETWORK_HTTP"
strings.starts_with(strings.to_lower(target.url), "http://www.")
strings.extract_hostname(target.url) = $hostname
strings.extract_domain(target.url) = $domain
match:
$hostname, $domain
outcome:
$url = array_distinct(target.url)

Here is the result. Notice the URL on the right and on the left we have the extracted portions of the URL that represent the hostname, which one might refer to as the fully qualified domain name in this case, as well as the domain.
Is everyone tracking so far? Cool! Let’s slightly alter the criteria by looking for all URLs that start with http, adding a count and sorting our results.
metadata.event_type = "NETWORK_HTTP"
strings.starts_with(strings.to_lower(target.url), "http")
strings.extract_hostname(target.url) = $hostname
strings.extract_domain(target.url) = $domain
match:
$hostname, $domain
outcome:
$url = array_distinct(target.url)
$event_count = count(metadata.event_type)
order:
$event_count desc
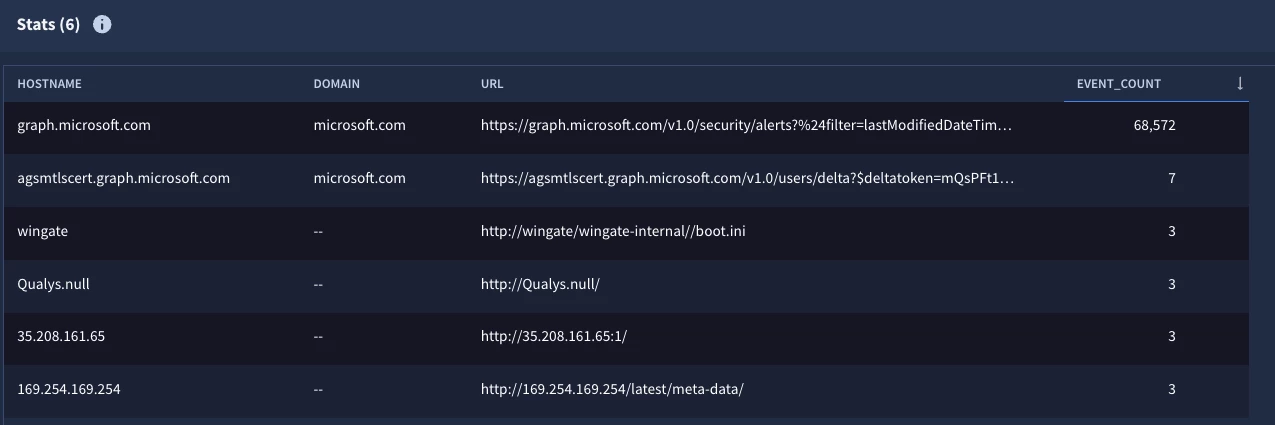
Notice this time, we have hostname values like graph.microsoft.com and agsmtlscert.graph.microsoft.com and domains like microsoft.com. That’s great because we can perform roll ups on the hostname or the domain to perform other statistical searches that jump to mind.
As we look at the other results, notice that while they have hostname values, they don’t have a domain value. In fact, even though they do have a hostname, it isn’t a fully qualified domain name. The extract functions are going to do their best with what is in the field they are provided, in this example the URL. Because the bottom two URLs contain an IP address after http://, extracting the IP address for the hostname and no domain being returned feels about right. The URL in the third row that starts with http://wingate/ extracts wingate for the hostname but again, there is no domain to work with, so no domain is available.
Where this could get murky is when we review the fourth line, http://Qualys.null/, which doesn’t contain a domain value either. This is because the function is dependent upon the value having a public suffix, that is an ICANN domain registered at publicsuffix.org. .null is not a public suffix so it is not goingto be extracted with the strings.extract_domain function.
These concepts apply to other fields beyond URLs. Here is a search for two domains that I have used with content I’ve built and may look familiar to readers of this blog series. One is a registered domain and the other is a domain ending in .local.
principal.user.email_addresses = /\\.local$/ or principal.user.email_addresses = /lunarstiiiness\\.com$/
strings.extract_hostname(principal.user.email_addresses) = $hostname
strings.extract_domain(principal.user.email_addresses) = $domain
match:
$domain, $hostname, principal.user.email_addresses
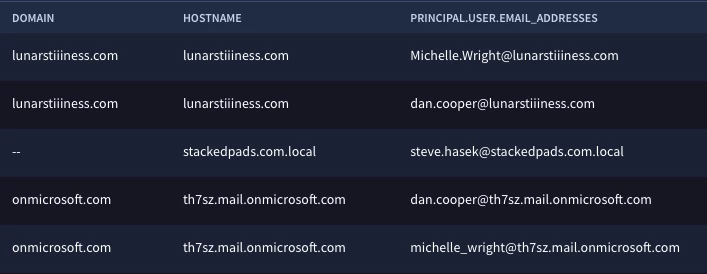
Notice the extraction of hostname and domain from the email address. The same principles apply as they did with the URL. It’s worth keeping in mind that even if the domain isn’t extracted, we could still extract the hostname and use it or apply additional functions if needed.
Let’s look at one more search example. This time we want to view DNS queries where the domain contains a country code at the end of the value, and extract those domains. The same concepts apply here for the domain extraction as in the other examples.
metadata.event_type = "NETWORK_DNS"
network.dns.questions.name = /\\.com\\...$/
strings.extract_domain(network.dns.questions.name) = $domain
match:
$domain
outcome:
$event_count = count(metadata.event_type)
order:
$event_count desc
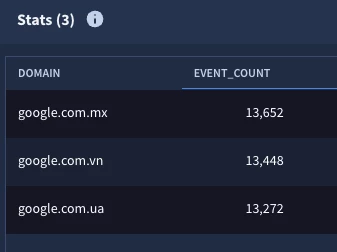
Notice that the extracted domain includes the country code since it is part of the domain.
Functions can be applied to both searches and rules, and strings.extract_domain is no exception. Let’s apply it in a rule. We can find all the DNS query events and then join those domains with our MISP data that has been ingested into the entity graph. By applying the strings.extract_domain function to the network.dns.questions.name field, we can identify the domain in this field, and we can compare that domain to values of other associated hostnames as well.
rule ioc_C2 {
meta:
author = "Google Cloud Security"
description = "Detect DNS queries associated with a C2 domain"
events:
$dns.metadata.event_type = "NETWORK_DNS"
$dns.network.dns.questions.name != ""
strings.extract_domain($dns.network.dns.questions.name) = $domain
$dns.principal.hostname = $hostname
$ioc.graph.metadata.product_name = "MISP"
$ioc.graph.metadata.entity_type = "DOMAIN_NAME"
$ioc.graph.metadata.threat.summary = "C2 domains"
$ioc.graph.metadata.threat.severity_details = "High"
$ioc.graph.entity.hostname = $domain
match:
$hostname over 5m
outcome:
$dns_query_name = array_distinct($dns.network.dns.questions.name)
$domain_name = array_distinct($domain)
condition:
$dns and $ioc
}
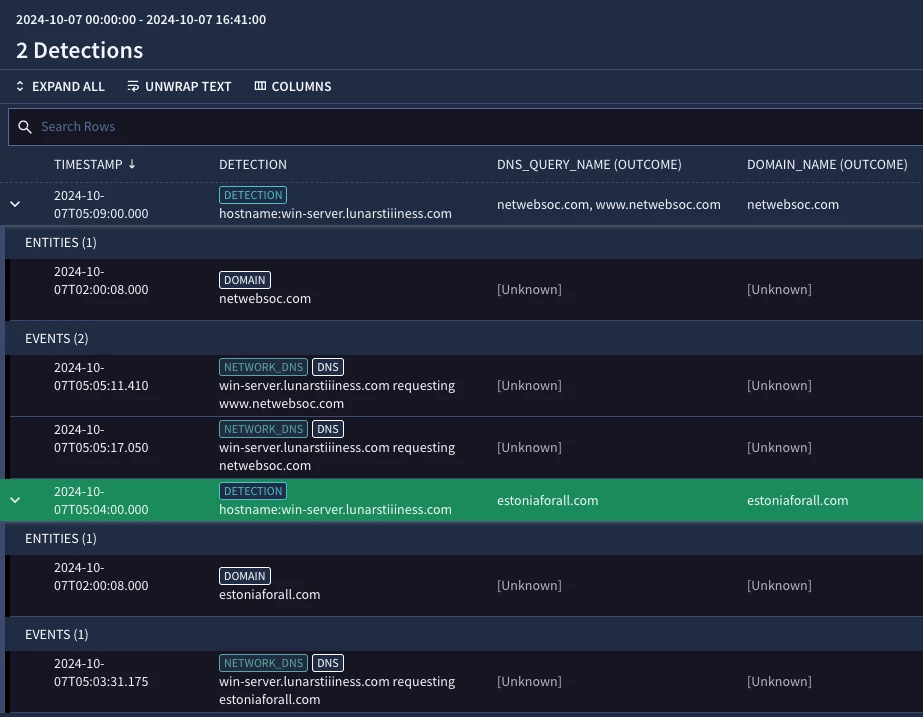
Notice when we test our rule, we get two different domain matches. Both detections contain a match based on the domain name itself, but in the first detection, we also matched the query of www.netwebsoc.com to the domain netwebsoc.com because we were able to use our function to extract the domain name first and then joining it to our MISP data in the entity graph!
I hope you have a greater appreciation for how the strings.extract_hostname and strings.extract_domain functions operate. These functions can be very helpful when working with URLs, email addresses, DNS queries and more. Rather than building regular expressions to extract these values, the functions provide a quick method to get to the values that are the most impactful to the analyst as they perform their hunts, investigations and building detections!