

A little about SecOps parsers
Google SecOps offers robust data handling across the entire data pipeline: ingestion, normalization, indexing, and enrichment. At the heart of this process is normalization, where our library of almost 700 parsers ensures compatibility with a wide range of log sources. The SecOps community benefits from a collaborative approach – as new log types become widely used, SecOps engineers develop new parsers for everyone to use. But what about custom-built applications or those without existing parsers?
Customized Normalization
The SecOps platform enables customers to create custom parsers, a vital feature for those tailored use cases. This ensures flexibility – if SecOps can ingest a log type, you have the tools to parse it. For reference, here's a list of supported data structures. To effectively craft custom parsers and normalize data into UDM, let's explore the basics of parser development.
Basics of Parser Development
Parser Development involves three major steps:
- Data Extraction: Pulling out the relevant information from the raw log.
- Data Transformation: Modifying the extracted data to fit desired formats or structures.
- UDM Assignment: Mapping the transformed data into SecOps's Unified Data Model (UDM) for standardization.
Google SecOps utilizes a pipeline called Gostash for parser development. Gostash is based on the filtering section of the open-source Logstash pipeline, allowing a streamlined focus on converting data fields to UDM. If you're familiar with Logstash development, Gostash will feel comfortable.
Data Extraction
To start the normalization journey, you start with raw logs. You have to extract the log “message” first to start transforming the data to UDM.
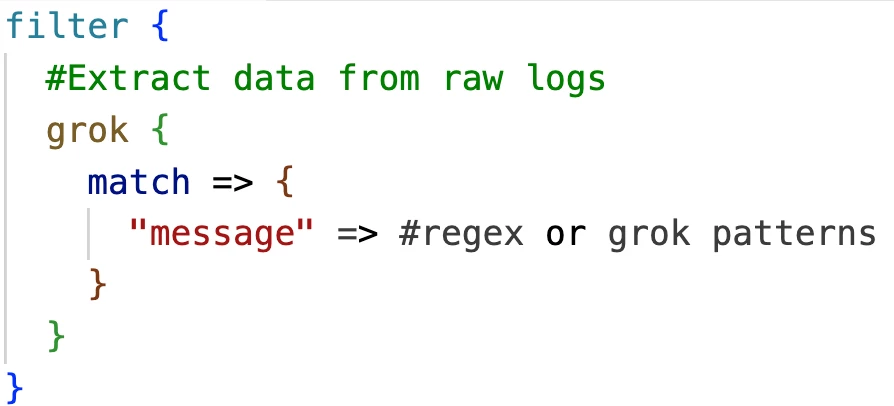
You can extract logs in a log of ways. You can see the various ways at the overview of log parsing.
Data Transformation & UDM Assignment
You can now start transforming values into the proper data types for the UDM fields in question. Take this example:
- I have an IP address in a field titled source_ip. I want to add this to the principal.ip field.
Any of the IP fields in UDM go through the process of validating the ip address to be in that format. If you need the value of a field to pass UDM validation, like principal.ip’s validation for ipv4/ipv6 values, you can convert the field like so:

Now, we can assign this to the principal.ip field:

Finally, we can send all of the fields under event to the @output, sending the normalized events to the indexing pipeline.

We now have a framework to parse logs!
Now I know what you’re thinking- “Darren! I understand the concepts of parsing, but how do I actually apply this to my use cases?”
I’m glad you asked.
Applied SecOps: Parsing
Before starting the normalization process, ask yourself these three key questions:
- What is the log telling me? Every log tells a story, revealing what happened or is happening within your system.
- What are the minimum required fields to normalize? Identify the essential data points needed to standardize the log within your system.
- What else do I need to make investigations fruitful for my SOC analysts? Consider which additional data will provide the most valuable context and insights for your security team.
By addressing these questions, you'll lay the foundation for effective normalization.
Understanding the Log's Story
Think of each log as a piece of a larger narrative. Let's consider a Windows event like this:
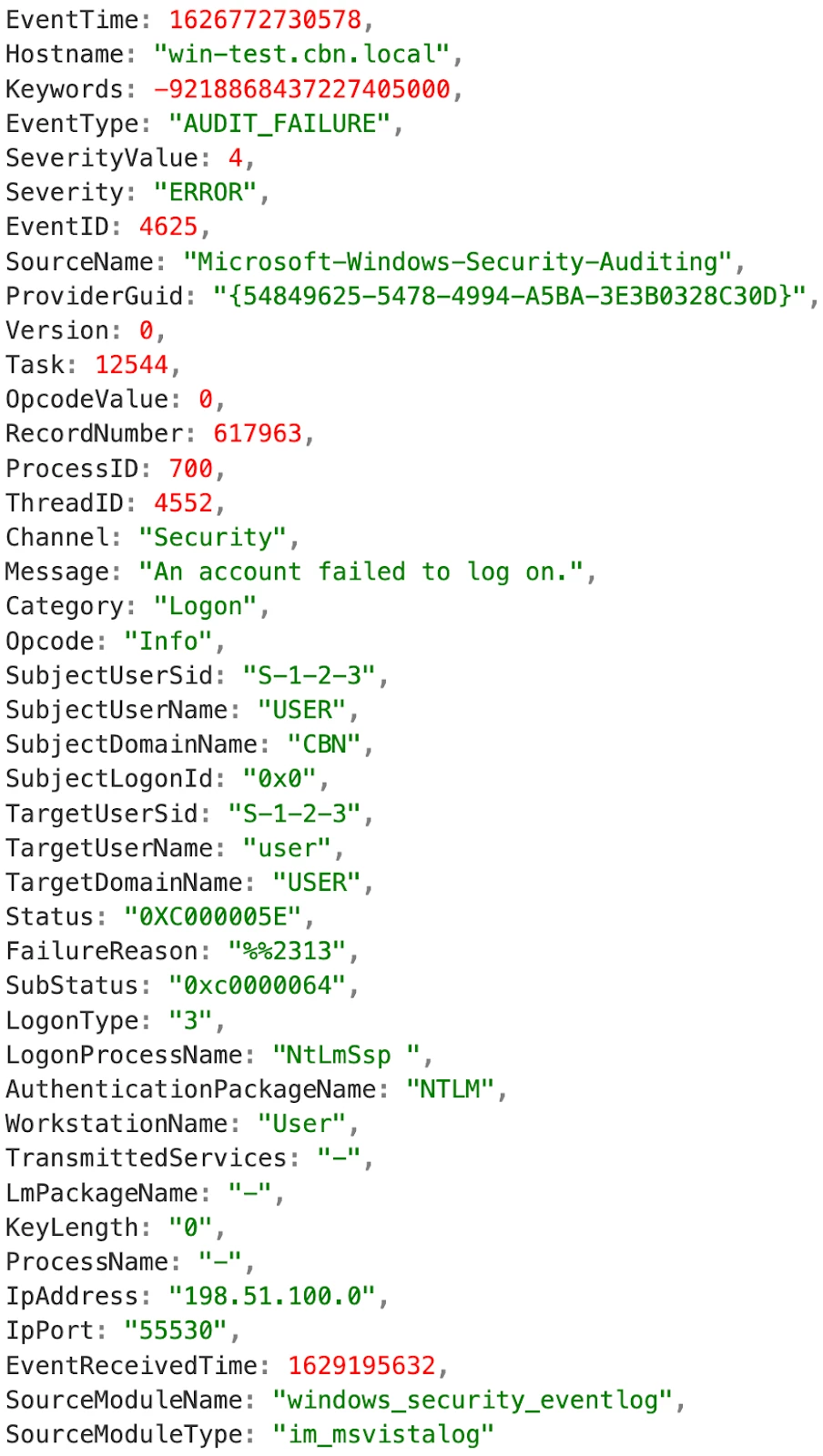
What the log is telling you:
- A failed login occurred: The log clearly shows an unsuccessful attempt to log into the system.
- Cause of failure: The reason for the failure was an incorrect password ("bad password attempt").
- User involved: The log identifies the username ("USER") associated with the failed login.
How this informs your normalization process:
- Understanding the event: This log entry represents a specific security event – a failed login attempt.
- Alignment with UDM: Your analysis correctly identifies this event as aligning with the USER_LOGIN event type within your Unified Data Model (UDM).
- Mapping Metadata: You can now confidently normalize the data by mapping the Windows EventID 4625 to the UDM field metadata.event_type with the value of USER_LOGIN.
if [EventID] == "4625" {
mutate {
replace => {
"event.idm.read_only_udm.metadata.event_type" => "USER_LOGIN"
}
}
}
What are the minimum required fields to normalize?
Now that we have the event type needed, we can consult the UDM Usage Guide.
- Consulting the Guide: The UDM Usage Guide confirms the essential fields required for USER_LOGIN events, including Metadata, Principal, Target, Intermediary, Network (if applicable), Authentication extension, and Security Result fields.
- Matching Log Data: Your analysis successfully identifies the corresponding data points within the raw log. For example:
- Principal: IpAddress, IpPort, and USER map to principal.user.userid and related fields.
- Target: TargetUserName and WorkstationName.
- Intermediary: hostname.
- Security Result: Determined by EventType, Severity, FailureReason, and Substatus.
- Handling Enumerated Values:
Understanding Enumerations: Enumerated fields are a unique field in UDM, where a display name corresponds to a numerical value. event_type is a prime example. Direct mapping from the raw log isn't possible with enumerated fields. You have to consult the UDM Field List to find the correct enumerated value for your raw data value.
Implementing the Mapping:
Some of the fields discovered can be mapped using the replace method:

There are other values that will be mapped into what is known as a repeated field in UDM. This can be done with the merge method, and you have 2 ways to merge based on the udm fields path level.
- Option 1: Direct field mapping. This is when the only field that is repeated is the udm field we are mapping data to
If we have a raw data field that is mechanism: “NETWORK”, then we assign the value in the following way:

- Option 2 is creating a local variable that contains the fields in the correct field path for the top-level UDM Field:
He is an example using intermediary and Security Result:

What else do I need to parse?
The most subjective aspect of normalization is determining which additional fields to extract. This decision hinges on your specific environment and security requirements. When discussing use cases, don't just focus on what logs need parsing – also consider what extra data will optimize detection and alert handling. Finding this balance between thorough normalization and avoiding UDM fatigue is crucial. Overly complex parsing can lead to an overwhelming volume of data, hindering efficient security operations.
You’ve parsed your first log pattern! This won’t be the last, and with continued log sources and opportunities, normalization will become second nature in no time! Look at this series of Adoption Guides from our Google SecOps experts on parser development.