
Just as organizations are starting to evolve their approaches to software supply chain security, the topic of AI supply chain springs up. The sprawling, complex landscapes of AI development and deployment bear a striking resemblance to the software supply chains we started to deal with. But here's the twist: AI throws in a whole new level of complexity — and risk.
Much broader and different than traditional software, the AI supply chain encompasses everything from data sourcing and model training to deployment and ongoing maintenance. Each link in this chain presents potential vulnerabilities, from poisoned training data to compromised model repositories. The stakes? Nothing less than the integrity, confidentiality, and availability of AI-powered systems that increasingly underpin critical infrastructure, decision-making processes and our society.
An insightful paper from Google covers their Secure AI Framework and its approach to a secure AI supply chain. Here are select insights:
AI Supply Chain Risks Are Real, Today
The AI supply chain, much like traditional software supply chains, is susceptible to various risks, including data poisoning, vulnerabilities in training frameworks, and model tampering. Malicious AI models are real, today – this is not a theoretical risk that may manifest in the future. Google’s paper on securing the AI software supply chain reminds us of the real-world examples of AI models being exploited to exfiltrate data or install backdoors. This highlights the urgent need for robust AI supply chain security.
Compromised AI models were found in 2023 and early 2024. The models appeared safe but actually contained dangerous code. When unsuspecting users downloaded them, the harmful code could steal data or install backdoors that let attackers take control of the users' machines.
At the same time, security measures don't work if developers won't or can't use them. As the example of GPG keys shows, security measures need to be usable and not overly complex for developers to adopt them.
AI Supply Chain Risks are Similar to Traditional Software
The Google paper highlights that AI development, while unique, shares many similarities with traditional software development lifecycles. These similarities allow for the adaptation of existing security measures like provenance and SLSA to the AI domain. According to the paper, “As with traditional supply chains, it’s important to find and fix bugs that get introduced into AI artifacts and infrastructure. With AI, though, a new class of dependencies emerges: the datasets which have been used to train a model.“ Adapting SLSA for AI works well: The Supply-chain Levels for Software Artifacts (SLSA) framework, initially designed for traditional software, is being adapted for AI. AI supply chain involves addressing challenges like the long and resource-intensive nature of AI model training that require changes.
Thus, traditional software supply chain attacks are happening in AI development. The same security risks that have affected traditional software development are now appearing in AI development. This means that existing software security measures should be used in AI development.
More interestingly, there are differences between securing AI and software supply chains:
- Data vs. Code: AI relies heavily on data, creating unique security challenges around data provenance, poisoning, and versioning — unlike software, which primarily relies on code. Version control for AI datasets is not as mature as that for traditional software code. This can make it difficult to track changes to datasets and manage their security.
- Opacity vs. Inspectability: AI models are opaque, making manual review impossible, unlike software code, which can be readily inspected and analyzed. AI training often comprises a series of ad hoc incremental steps that are not recorded in any central configuration.
- Emphasis on Provenance: Provenance (a detailed, tamper-proof record of origin and modifications) is crucial for AI due to the risks of data poisoning and model tampering, going beyond typical software requirements.
The Opacity of AI Models
The paper emphasizes that AI models, particularly large language models (LLMs), are inherently "opaque." Their behavior is heavily influenced by their weights, which are difficult to analyze due to their large number and binary format. This opacity poses a unique challenge for security leaders who are used to being able to inspect and understand the inner workings of software. The behavior of an AI model is heavily influenced by its weights, yet given the large number of weights and binary format, it is not humanly possible to analyze the weights to predict what a model may do.
Provenance is Key
The concept of provenance, a tamper-proof record of an artifact's origins and modifications, is extended to AI models and datasets. Provenance helps track dependencies, ensure integrity, and mitigate risks like data poisoning and model tampering. The authors discuss the complexities of data provenance in AI, including questions about the level of detail to capture (e.g., dataset names versus individual data points) and the need for cryptographic integrity checks for datasets. The ecosystem for storing, changing, and retrieving datasets is less mature than that for code management, but it is required for AI. Tamper-proof provenance is indispensable for securing AI artifacts and data, enabling users to verify the identity of the model producer and confirm the model's authenticity. Security teams should prioritize the implementation of robust provenance tracking mechanisms to ensure the integrity and traceability of AI models and datasets.
AI attacks can be mitigated with provenance information. This involves documenting what went into an AI model during development, such as datasets, frameworks, and pretrained models. This information can help identify potentially problematic models. Provenance information is crucial for mitigating AI attacks and ensuring the security of AI models. By meticulously documenting the various components that contribute to an AI model's development, including the datasets used, the frameworks employed, and any pretrained models incorporated, a comprehensive record of the model's lineage is established. This provenance information serves as a valuable resource for identifying potential vulnerabilities and risks associated with specific AI models.
For example, if a dataset used in training an AI model is known to contain biases or inaccuracies, the resulting model may exhibit similar flaws. By tracking the provenance of the dataset, it becomes possible to identify and address these issues before they can be exploited by attackers. Similarly, if a pretrained model is found to have security vulnerabilities, any AI models that incorporate it may also be at risk. Provenance information allows for the identification and mitigation of these risks, ensuring that AI models are robust and secure.
Furthermore, provenance information can also be used to track the evolution of AI models over time. As models are updated and refined, it is important to maintain a record of the changes that have been made. This information can be used to identify any unintended consequences of these changes, as well as to track the effectiveness of different approaches to AI development.
Overall, provenance information plays a critical role in securing the AI supply chain. By providing a transparent and auditable record of the development process, it enables stakeholders to identify and address potential risks, ensuring that AI models are trustworthy and reliable.
Conclusions
To conclude, the paper offers practical guidance for practitioners, emphasizing the capture of comprehensive metadata, increasing integrity through cryptographic signing, organizing metadata for effective querying and controls, and sharing this information to foster trust and transparency.
For example, capture enough metadata to understand the lineage of each artifact (models or otherwise!). You want to be able to answer basic questions: where an artifact came from; who authored it, changed, or trained it; what datasets were used in training it; and what source code was used to generate the artifact.
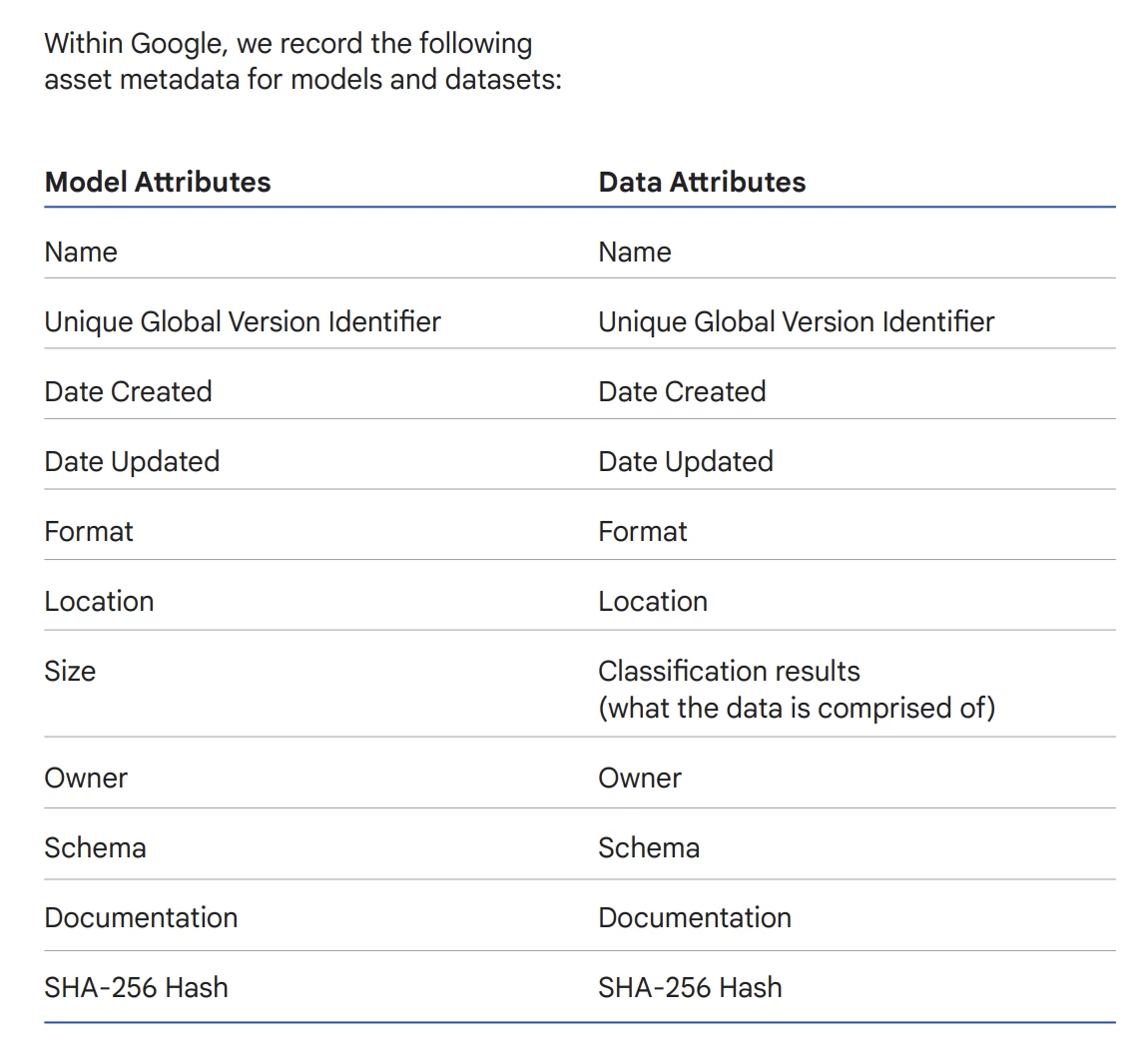
Next, organize the information to support queries and controls. Later on, the metadata should be captured during the artifact’s creation in a non-modifiable, tamper-evident way. Finally, as a best practice, share the metadata you capture in an SBOM, provenance document, model card, or some other vehicle that will assist other developers.
Still, collective action is key to securing the AI software supply chain. No matter how self-reliant an organization is, there will always be dependencies, datasets, and other shared components involved. By diligently applying established software supply chain security practices and carefully tracking datasets, organizations can bolster their defenses against malicious attacks and recover more quickly from unintended vulnerabilities.
Read the full paper and other AI security resources that compare AI and traditional security