


This post will discuss briefly how to modify MSV Scheduled jobs programmatically using MSV API.
Python with several external libraries including Pandas will be used in this demo. The msvlib_simple.py is a simple library file I coded with some wrapper functions for demo purposes. I personally prefer using interactive python interpreters for this task. During this demo you would need to replace "app.validation.mandiant.com" with your MSV director hotsname if you are using an on-prem instance. Also we will use this notation as a shorhand for the API calls with some comments about the body if needed;
return = Function name in Library(): HTTP Method : API Endpoint : Comment about Payload
First prepare a credentials file credentials.txt with this format for example ;
[hdr]
Content-Type = application/json
Accept = application/json
Authorization = Bearer xxx=
Mandiant-Organization = UUID xxxx
url_base = https://app.validation.mandiant.com/
The API keys are generate from https://app.validation.mandiant.com/users/user_prefs , The Mandiant-Organization ID is only available for the SaaS version under https://app.validation.mandiant.com/organizations
The demo script starts by importing pandas and msvlib_simple. The function readConfig() will parse the required credentials key-value format to facilitate environment variables assignment.
The first API call will fetch the scheduled jobs in a Pandas DataFrame then export the results in a CSV file -after some optional columns renaming-
scheduled_jobs = ScheduledJobs() : GET : scheduled_actions : Empty Payload
There are some important fields to highlight ;
- id : The scheduled job ID, this is a unique ID for the scheduled job. You can have multiple scheduled jobs for the same simulation (for example; a limited 1-actor weekly and another all-actors comprehensive monthly Data Exfil simulation) and each will have different scheduled job ID but similar simulation.
- action_type : Indicates whether the scheduled job is a simulation/evaluation "sequence" or a single action "action".
- simulation_id : The ID of the simulation -Sequence or Evaluation- used in the scheduled job, it will be null for a single action jobs. This ID represents the current simulation version, and is different from the simulation VID. Think of it as a version ID of the simulation, each simulation will have a unique VID but multiple simulation IDs with the active one being the most recent.
- sim_action_id : Same but for actions, again this is not the action VID but the action current active ID.
- params: These are the variable content parameters applied to this job, for example choosing a different port for the network actions in this job.
You could export the results in a CSV. For example, this is a sample result indicating mapping between the UI entries and the API call return values ;


To change the schedule of an existing scheduled job, you could use the attached csv template "JobScheduleEdit.csv" to write down your required modifications. The main paramters in the template are ;
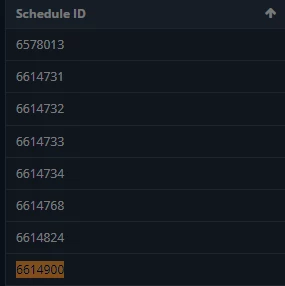
- job_id : The Schedule ID in the UI
 .
. -
repeat_job_period_number: the schedule frequency number. e.g. Execute the action every 100 units
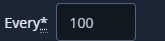
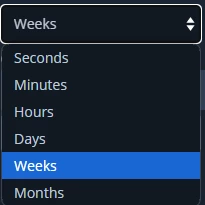
- repeat_job_period_type : The frequency unit, could be "Days" or any value from this drop down list. e.g. execute the action every n days
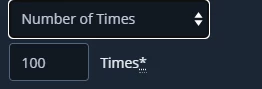
- Repeat_job_count : How many times the job will be repeated -if repeated- until the schedule stops. e.g. Repeat the action only 100 times not indefinitely
 OR
OR  .
. - repeat_job_times_selector: Can be either 'indefinitely' in case "Until Canceled" or 'number' in case "Number of Times" is selected in (4).
- repeat_week_days : can be any of ; M,T,W,Th,F,S,Su or null in case the weekday is not applicable
 . In the CSV you will need to insert them as "S|M" for example.
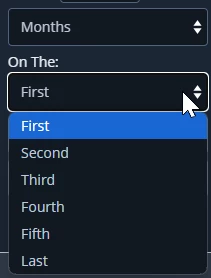
. In the CSV you will need to insert them as "S|M" for example. - repeat_monthly_frequency : can be either of 'first, second, third, fourth, last' when the frequency unit in(3) is month
- schedule_job_datetime : This is the start date of the schedule
 .
. - repeat_job_selector : Can be "on" for repeating jobs.
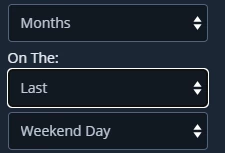
- repeat_day_of_the_week : Can be a weekday ; "Sunday" or "Friday",.., "Weekend Day" or "Day" or "None". Depends on the configuration of "Months" frequency unit
For other possible configurations ; You could set a dummy schedule in the UI, then import its configuration using the APIs to explore other combinations and/or paramters.
The second half of the script will loop through the entries and update the scheduled jobs. For example based on jobsScheduleEdit.csv ; the script will fetch the Job ID 6614900, then change the CSV file by adding the currently configured job 6614900 json payload from MSV but just modifying the time schedule settings (like "repeat_job_count" ) using these API calls.
getScheduledJob() : GET : scheduled_actions/{scheduledJobId} : Empty payloadeditScheduledJobs() : PUT : scheduled_actions/{scheduledJobId} : Payload from the existing job
#msvlib_simple.py
import requests
import json
import configparser
import os
import urllib3
import time
def writeConfig(configFileName='cre.txt', apiToken='vdm1_zzzzzz=', UUID=None, folderName='.'):
configFileName=folderName+"/"+configFileName
os.remove(configFileName) if os.path.exists(configFileName) else noop
f=open(configFileName,mode="a")
f.write("[hdr]\\n")
f.write('Content-Type = application/json \\n')
f.write('Accept = application/json \\n')
bearerToken=f"Bearer {apiToken}"
f.write(f'Authorization: {bearerToken}\\n')
if UUID is not None:
f.write(f'Mandiant-Organization=UUID {UUID}\\n')
f.close()
def readConfig(configFileName='cre.txt',folderName='.'):
configFileName=os.path.join(folderName, configFileName)
config = configparser.ConfigParser()
config.read(configFileName)
keys=[key for key in config[config.sections()[0]]]
values=[config[config.sections()[0]][key] for key in keys]
headers={k:v for (k,v) in zip(keys,values)}
return (headers)
def runAPI(endpoint='topology/nodes', verb='GET'
, payload=json.dumps({}), headers_msv=json.dumps({})
,url_base = 'https://app.validation.mandiant.com/'
,params=None
, printing=False ):
url_msv=f"{url_base}{endpoint}"
successful = False
while not successful:
try:
res = requests.request(
method=verb
, url=url_msv
, params=params
, headers=headers_msv
, data=payload
, verify=False
, timeout=600
)
successful = True
except requests.exceptions.RequestException as e:
print (f"Error : {e}")
time.sleep(60)
if printing==True : print (res.url)
if printing==True : print (res.request)
if printing==True : print (res.text[:100])
if res.text!='':
return json.loads(res.text)
else :
return res.text
def getScheduledJobs ( headers_msv
, url_base
payload = {}
payload=json.dumps(payload)
jobsScheduled=runAPI(endpoint=f"scheduled_actions"
, verb='GET'
, payload=payload
, headers_msv=headers_msv
, url_base=url_base
)
return jobsScheduled
def getScheduledJob ( headers_msv
, url_base , scheduledJobId):
payload = {}
payload=json.dumps(payload)
jobsScheduled=runAPI(endpoint=f"scheduled_actions/{scheduledJobId}"
, verb='GET'
, payload=payload
, headers_msv=headers_msv
, url_base=url_base
#, printing = True
#,params=msv_params
)
return jobsScheduled
def editScheduledJobs ( headers_msv
, url_base, scheduleId , payload):
#payload = {}
payload=json.dumps(payload)
jobsScheduled=runAPI(endpoint=f"scheduled_actions/{scheduleId}"
, verb='PUT'
, payload=payload
, headers_msv=headers_msv
, url_base=url_base
#, printing = True
#,params=msv_params
)
return jobsScheduled#main.py
#!/usr/bin/env python
# coding: utf-8
# In[12]:
from msvlib_simple import *
# In[14]:
import pandas as pd
# In[ ]:
# In[11]:
folderName='.'
configFileName='credentials.txt'
# In[13]:
headers_msv=readConfig(configFileName = configFileName
, folderName = folderName
)
# In[33]:
url_base = headers_msv['url_base']
payload=json.dumps("")
# In[17]:
#Dump the list of existing scheduled Jobs
jobsScheduled = getScheduledJobs( headers_msv
, url_base )
#Save them into a Pandas DataFrame for Easier Processing
jobsScheduledPd=pd.DataFrame(jobsScheduled)
# In[19]:
jobsScheduledPd
# In[21]:
jobsScheduledPd.to_csv('jobsScheduled.csv')
# In[19]:
#Read the list of Jobs Schedules to be edit, the CSV list "simulation_id" is the Job ID in the UI
jobsScheduleEdit = pd.read_csv('jobsScheduleEdit.csv')
# In[21]:
jobsScheduleEdit
# In[23]:
jobsScheduleEdit.fillna('',inplace=True)
jobsScheduleEdit['repeat_week_days']=jobsScheduleEdit.apply(lambda row:row['repeat_week_days'].replace("|",","),axis=1)
jobsScheduleEdit
# In[35]:
#Loop through the jobsScheduleEdit.csv list
for i, row in jobsScheduleEdit.iterrows():
#Extract the existing Job ID details
scheduledJob = getScheduledJob( headers_msv
, url_base , row['job_id'])
#Copy the existing Job ID payload from MSV
currentPayload = json.loads(scheduledJob['params'])['run_time_params']
#The new Payload for the job will be composed of the existing MSV payload "params" field
# Added to the CSV new entries, i.e. Same job details but only change the schedule
newPayload=row.to_dict()
newPayload.update({'params':currentPayload})
# Push the new payload using PUT method with the same Job ID
evalEditAttempt=editScheduledJobs( headers_msv, url_base, row['job_id'] , newPayload)
# In[ ]:
#jobsScheduleEdit.csv
##Sample CSV Entry to modify the schedule of Job ID 6614900
job_id,repeat_job_period_number,repeat_job_count,repeat_job_period_type,repeat_job_times_selector,repeat_week_days,repeat_monthly_frequency,schedule_job_datetime,schedule_run_now_selector,repeat_job_selector,repeat_day_of_the_week,job_name
6614900,100,100,days,number,S|M,last,2024/09/20 00:00:00,schedule,on,Sunday,jobNameTest