

Authors:
Bhavana Bhinder, Security, Privacy and Compliance Advisor, Office of the CISO
RK Neelakandan, Software Quality and Solutions Lead • Engineering - Health
Odun Fadahunsi, Senior Security, Risk and Compliance Advisor, Office of the CISO
In the rapidly evolving landscape of healthcare and life sciences (HCLS), AI is no longer a theoretical concept—it’s actively identifying drug targets and assisting in radiological diagnoses. However, bringing AI into regulated GxP (Good Practice such as Good Manufacturing Practices - GMP or Good Clinical Practices - GCP) environments introduces unique challenges. The core issue isn't just "Does it work?" but rather, "Can we prove it works consistently and safely, and do we understand the risk it introduces?". Most significantly, this requires the rigorous validation of the AI system.
To answer this, we need a new conceptual model for evaluating AI risk with respect to GxP validated environments, one that looks beyond simple predictive accuracy and doesn’t treat all models as simply ‘AI’.
The Risk Approach: Probability, Impact and Autonomy
The fundamental rubric for assessing AI risk in a regulated environment requires evolving beyond traditional risk management frameworks. Historically, ISO 31000 has defined risk as a product of Likelihood x Impact; however, in the context of modern AI, risk is not merely about the severity of a failure, it is fundamentally tied to the inherent fallibility and stochastic nature of the system. This necessity for a more nuanced approach is echoed in the field of optimal control, where Wang and Chapman (2022) demonstrated that assessing autonomous systems using 'probability alone' is insufficient, requiring frameworks that prioritize risk-averse behaviours. For HCLS, instead of optimizing for "average" performance, these systems must prioritize risk-averse behaviors—designing the AI to specifically avoid "worst-case" or "tail" scenarios, even if they are statistically rare.
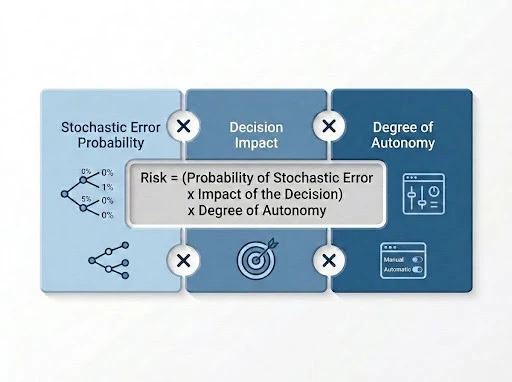
By adapting this foundational research on AI fallibility into a GxP context, we recognize that as systems transition from tools to agents, the risk profile shifts. To address this, our proposed assessment rubric augments the traditional model to account for the unique compounding risks of agentic independence. We propose that risk in regulated AI environments be quantified as Risk = stochastic error x decision x D(Autonomy). This formula ensures that 'Degree of Autonomy' acts as a critical scalar, reflecting how an agent's independence can amplify a single stochastic error into a cascade of high-impact regulatory consequences.
Risk = (Probability of Stochastic Error x Impact of the Decision) x Degree of Autonomy*
*This approach evolves standard risk calculations to account for the stochastic nature of AI systems, drawing on concepts explored in recent AI research on Risk-averse autonomous systems and Fully autonomous AI agents.
-
The Probability of Stochastic Error: Acknowledges that AI systems are probabilistic and will inevitably produce incorrect outputs (e.g. hallucinations, false positives, false negatives).
-
Impact: The GxP consequence of an error on patient safety, product quality, data integrity or quality systems.
-
Autonomy: The speed and friction level at which the error reaches the real world. Does a human review the output first or does the AI act directly and can the human even detect it?
The more autonomy we grant an AI system, the greater the potential risk if its probabilistic inference is incorrect. We require a modified classification framework to categorize GxP systems based on model complexity, explainability, and autonomy. Traditional verification methods, such as Computer System Validation (CSV), are limited for the dynamic, non-deterministic nature of modern machine AI systems, as they were designed for a different technological paradigm.
The fundamental shift in software validation arises from the transition from deterministic to stochastic systems. Traditional software operates on rule-based logic where input "X" consistently yields output "Y." Due to this predictability, CSV frameworks effectively employ Requirements Traceability Matrices (RTM) to execute binary pass/fail test scripts against fixed logic.
Conversely, AI relies on probabilistic logic. Given an input "X," these systems provide a result based on statistical confidence—for example, a 95% probability of "Y" and a 5% probability of "Z." As inference engines rather than simple calculators, they are inherently non-deterministic and can generate varying outputs for identical inputs based on context and trained weights.
Consequently, traditional binary pass/fail testing is insufficient; a ‘passing’ unit test may confirm code stability but fails to address the reliability or safety of the agent's probabilistic behavior. Validation must therefore evolve to demonstrate that a model operates within acceptable statistical tolerances across representative datasets, transitioning from static scripts to continuous, risk-based verification.
Given that modern Ai systems are stochastic, we must transition from binary testing to probabilistic validation- proving that the model operates within an acceptable statistical tolerance (e.g. maintaining an F1 score > 0.90) across a representative dataset, rather than passing a static functional script. We need a new classification approach to dissect GxP systems into risk categories depending on the model complexity.
We will explore a scaled model of validation, moving from basic validation levels to the frontiers of self-learning models.
Defining the Risk-Autonomy Scale for GxP
As model complexity increases, the degree of model autonomy and the probability of stochastic error increase. Each tier introduces new validation requirements, building on the tier before it.
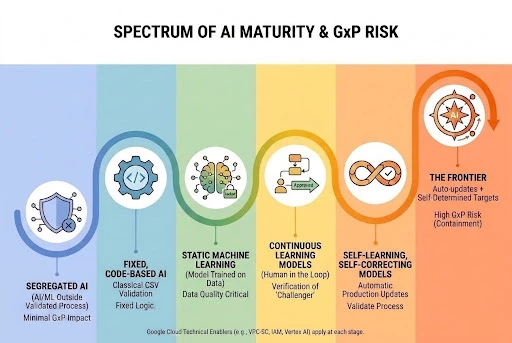
Tier 1: Segregated AI
This involves using AI for manufacturing, clinical, and laboratory purposes that do not directly feed into production GxP decisions. Validation here focuses on boundaries rather than the model itself. We must ensure unvalidated AI outputs cannot influence regulated workflows without a formal, validated manual bridge. Technical perimeters must be paired with Standard Operating Procedures (SOP) and training. This prevents the dangerous practice of ‘Shadow AI’- instances where users might manually copy-paste outputs from an unvalidated AI tool into GxP systems.
Google Cloud Technical Enablers:
-
Virtual Private Cloud (VPC) Service Controls: Establish a perimeter around your ML experimentation environments. Use VPC-SC to create security perimeters that prevent data moving between the R&D and production VPCs.
-
Cloud IAM (Identity and Access Management): Implement least-privilege principles. Only approved researchers should have access to projects that are directly related to their work for the period needed with clear separation from research to production environments . Use IAM Conditions and Cloud Storage buckets to restrict access further (e.g., access only via a corporate network or specific time windows).
Tier 2: Deterministic Algorithms/Rules-Based Systems
This tier relies on human-coded logic rather than trained stochastic weights. Because the logic is fixed in the code, it acts deterministically and can be governed by classical Computer System Validation (CSV) and GAMP 5 methods. We can use test scripts to verify every possible path.
Google Cloud Technical Enablers:
-
Continuous Integration/Continuous Deployment (CI/CD) with Cloud Build: An automated pipeline enforces a validated pathway. Crucially, the pipeline serves as a deterministic wrapper around stochastic elements. To convince regulators of a 'ground truth' state, Cloud Build does not rely on models grading other models (which creates an unverifiable recursive loop). Instead, the pipeline runs the model against an immutable, human-curated 'golden dataset' with fixed historical outcomes. While the model's underlying nature is probabilistic, the verification gate itself is binary and deterministic: the build passes or fails based on whether the model hits rigid, predefined statistical tolerances (e.g., maintaining an F1 score $> 0.95$).
-
Binary Authorization (BinAuth): Guarantees that only software images built and signed by the approved CI/CD pipeline are deployed to production clusters like Google Kubernetes Engine (GKE).
Tier 3: Static Machine Learning
This is where true ML begins. A model is fine-tuned on historic data and "locked" for production use. It does not self-update on new production data. Data quality becomes the new code; validation must ensure the training data is representative, unbiased, and clearly documented.
Because the real world is not static, a locked model will inevitably degrade over time as patient populations, devices, or diseases shift. Therefore, validation at this tier must encompass continuous monitoring and procedural friction.
Human-in-the-Loop (HITL): For high-impact models, procedural design must enforce a HITL architecture. The AI acts in an advisory capacity (Human-over-the-Loop), requiring a qualified human to review and execute the final GxP decision.
Google Cloud Technical Enablers:
-
Data Quality Validation (BigQuery, Dataform and Knowledge Catalog): Before training data enters Gemini Enterprise Agent Platform, use Dataform within BigQuery to create automated data validation tests (e.g., check for null values, verify data ranges, validate business rules). Knowledge Catalog supports Governance foundation, as it automatically collects technical metadata from selected Google services such as BigQuery and establishes a trusted data foundation enabling data quality checks and policy based governance.
-
Feature Store: Use a Agent Platform AI Feature Store as the validated "single source of truth" for features used in training and serving. This ensures that the same, pre-validated features are used in both environments, preventing train-serve skew.
-
Model Performance Monitoring with Agent Platform Model Monitoring: Even a static model must be validated. Validation here involves verifying the choice of training data and the initial performance metrics. Post-deployment, we use Agent Platform Model Monitoring to watch for prediction drift and feature attribution drift. If the model starts seeing data in production that is significantly different from its training data, a drift alert is triggered, prompting a validation review.
-
Gen AI Evaluation Services on Agent Platform: By providing mathematical evidence of robustness, this rigorous stress-testing addresses the 'intended use' validation mandates for complex, non-deterministic systems. Gen AI evaluation services lets you see how a model performs based on the specific task and criteria that you set and by applying model fine tuning evaluation on a consistent evaluation criteria for every run.
-
Model Cards: Transparent documentation is a regulatory mandate. Use Model Cards to automatically document model performance, intended use cases, training data characteristics, and limitations, making audit readiness seamless.
Moving Beyond "Validation Levels" to Real-Time Verification
This is where the paradigm shifts from periodic, point-in-time validation to verification of dynamic processes.
Tier 4: Continuous Learning Models – Human in the Loop
These models adapt continuously based on new data but require human oversight for final approval before production deployment. The core validation challenge is ensuring that a new model version offers improved safety and performance without compromising GxP integrity. Effective oversight relies on operational performance data and robust, automated gateways that provide full auditability and explainability before approval. Implementing integrated workflow engines to route these updates to authorized Quality Assurance (QA) personnel or subject matter experts for formal review is critical for maintaining regulatory compliance.
Google Cloud Technical Enablers:
-
Agent Platform Model Evaluation & Comparison: The AutoML or custom training pipelines must include automated evaluation phases (e.g., evaluating against a hold-out dataset). The results can be compared side-by-side with the current production model.
-
‘Canary’ Deployments and Traffic Splitting (GKE or Cloud Run): Before the human-approved model becomes the default, a statistically small percentage (that would be within predefined risk tolerance) of production traffic can be "canaried" to the new model. Monitoring detects any regression in performance or unexpected behavior before full exposure.
-
Agent Platform Lineage: When pipelines are created using Agent Platform Pipelines, the pipeline lineage—including model lineage—captures metadata from model training and evaluation, as well as training, test, and evaluation data. This supports critical validation governance criteria, such as verifying which model was in production at a given point in time.
Tier 5: Self-Learning, Self-Correcting Models
In this stage, the model automatically updates to production. Humans provide the optimization targets, but the agent executes the path. This is a significant risk increase. We are no longer validating the model; we are validating the process by which the model decides to validate and deploy a new version. We must verify that the automated system has chosen correct optimization targets and correctly self-approved a model version. Assurance is required through the entire process and the need for continuous validation is clear.
Google Cloud Technical Enablers:
-
Agent Platform Pipelines (KFP-based): The entire lifecycle becomes an executable code object. We do not validate the model directly; we perform a one-time validation of the pipeline itself. This pipeline contains immutable gates that eliminate recursive evaluation risks: automated data drift checks -> automatic re-training -> automatic re-evaluation against a static, human-verified gold-standard benchmark set. By anchoring the automated evaluation to this fixed empirical baseline, we maintain a regulatory 'ground truth' even as the model iterates dynamically. All results are captured via mandatory, immutable audit logging.
-
Production Sentinel - deploy through Google Security Operations log ingestion and Agent Platform Model Monitoring. In real time the Production Sentinel monitors for behavioral drift, data skew, prediction drift, and infrastructure anomalies and alerts if a change is outside the expected change control workflow. The Sentinel would deem an event change outside of the parameters of the compliance model and flags the deviation immediately.
-
Cloud Logging & Cloud Audit Logs (Data Access & Admin Activity Logs): Every self-driven action must be logged immutably. Use Cloud Audit Logs to track not only when a model was updated but to programmatically confirm that the mandatory data drift and performance metrics were met before the automated system allowed the promotion.
Tier 6: The Frontier – Self-Learning, Self-Correcting, Self-Determining
This represents the extreme edge of the current risk landscape for GxP: model auto-updates on production where the model sets its own targets.
At this level, we must ask: if fundamentally GxP exists to ensure the safety, efficacy, and quality of regulated products in a controlled environment, how can self-determining AI systems meet this threshold? Do the risks outweigh the benefits? Critically, how do other industries manage self governing autopilot systems? This is likely beyond the risk appetite for directly affecting patient safety or drug release in today's regulated environment. While technically feasible today, Tier 6 currently sits beyond the risk appetite for systems directly affecting patient safety or drug release. However, building the architecture for Tiers 3, 4, and 5 prepares organizations for this eventual frontier.
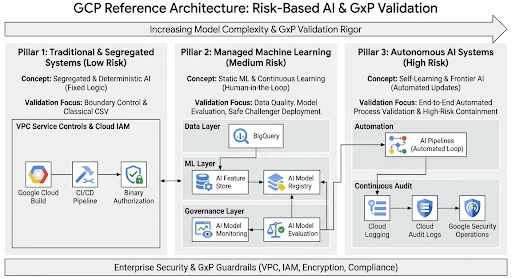
Reference Architecture
The architecture diagram below illustrates this progression, summarizing how validation requirements and risk levels evolve across the six tiers. It provides a visual roadmap for navigating the journey from segregated AI systems to the self-determining frontier.
Conclusion
The journey from manual GxP processes to AI automation is not a simple "on/off" switch. It's a spectrum of risk that demands a spectrum of control and validation technologies.
By understanding risk as a function of control impact and autonomy, and using the right Google Cloud tools at the right level, we can confidently bring the next generation of life-saving AI technologies to market in a validated and compliant way.
To learn more about how Google Cloud supports the Life Sciences industry: