



OK, I promise we will build rules using the graph_append in this blog post! Our previous post covered the data preparation step which ensured that the data table had the appropriate fields in it. These include mapping to the metadata.interval.start_time.seconds and metadata.interval.end_time.seconds fields which will drive which entities are considered when the rule triggers, as well as other fields like metadata.entity_type and metadata.source_type that are generally used to make rules more performant when writing rules using the entity graph.
With that out of the way, we can review the syntax and apply it to our rules.
graph_append
The concept of graph_append is pretty simple, we are appending rows from the data table to rows that exist within the entity graph and use both in a rule. This can be incredibly useful when we quickly need to add a set of users to a rule but we might not have had the time to add the data to the entity graph.
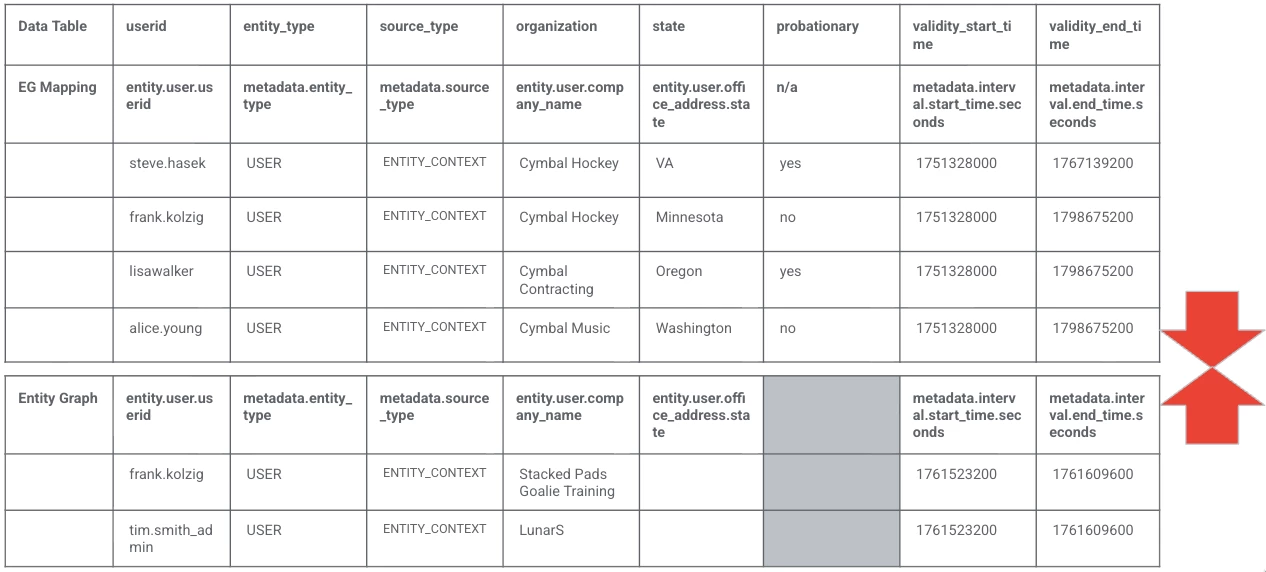
For our purposes today, here is what our user list will look like. This is based on the data we loaded in our previous blog. On the top, we have a data table with mappings to the entity graph and on the bottom we have two users from our entity graph represented. The graph_append command will merge these together to create a superset of data that the rule will run against.
It’s important to remember that this append is ephemeral, it only exists in the context of the rule it is running in. The append does not permanently write these values from the data table into the entity graph or vice versa!
It’s also worth noting that the syntax for graph_append is a little different from the graph_override and graph_exclude commands. They used joins to link the data table and the entity graph, where graph_append defines within square brackets the event variable that represents the entity graph followed by a comma and then the name of the data table that is being appended to it.
setup:
graph_append [$graph, %append_table]
This really basic example is using the event variable graph to represent the entity graph and the data table is named append_table. Pretty simple.
Starter Rule
To highlight how we can use graph_append in our rule, we are going to use the following rule as our starting point and build out from there. This initial search is essentially looking for process launch events for users and aggregating them by a common principal.hostname within a 15 minute window. It’s not super fancy but serves as a good place to start as we start adding in the entity graph and our data table.
rule process_launch_graph_append {
meta:
author = "Google Cloud Security"
description = "Detect process launch events and how the entity graph can be used with data tables to enrich a rule with Data Table Append."
type = "detection"
data_source = "sysmon"
platform = "Windows"
severity = "Info"
priority = "Info"
events:
$process.metadata.event_type = "PROCESS_LAUNCH"
$process.principal.user.userid != ""
$process.principal.user.userid != /\$$/
$process.principal.user.userid != "admin"
$process.principal.user.userid = $userid
$process.principal.hostname = $hostname
match:
$hostname over 15m
condition:
$process
}
Adding the Entity Graph to our Rule
Let’s add the entity graph into the rule. The rows in the events section that start with $graph are the rows that link the events to the entity graph based on a common userid. Notice that we have criteria for both the entity_type and the source_type. Having criteria for these fields is generally considered a best practice as it will improve rule performance and this will become crucial when we add the data table.
rule process_launch_graph_append {
meta:
author = "Google Cloud Security"
description = "Detect process launch events and how the entity graph can be used with data tables to enrich a rule with Data Table Append."
type = "detection"
data_source = "sysmon"
platform = "Windows"
severity = "Info"
priority = "Info"
events:
$process.metadata.event_type = "PROCESS_LAUNCH"
$process.principal.user.userid != ""
$process.principal.user.userid != /\$$/
$process.principal.user.userid != "admin"
$process.principal.user.userid = $userid
$process.principal.hostname = $hostname
$graph.graph.metadata.entity_type = "USER"
$graph.graph.metadata.source_type = "ENTITY_CONTEXT"
$graph.graph.entity.user.userid = $userid
match:
$hostname over 15m
outcome:
$user = array_distinct($graph.graph.entity.user.userid)
$type = array_distinct($graph.graph.metadata.entity_type)
$org = array_distinct($graph.graph.entity.user.company_name)
$state = array_distinct($graph.graph.entity.user.office_address.state)
$interval_start = array_distinct(timestamp.get_timestamp($graph.graph.metadata.interval.start_time.seconds))
$interval_end = array_distinct(timestamp.get_timestamp($graph.graph.metadata.interval.end_time.seconds))
condition:
$process and $graph
}
We need to add the event variable of $graph to the condition section of the rule and we have added an entire outcome section that is outputting values from the entity graph. We are doing this mainly to view the output of these fields in the detections below.
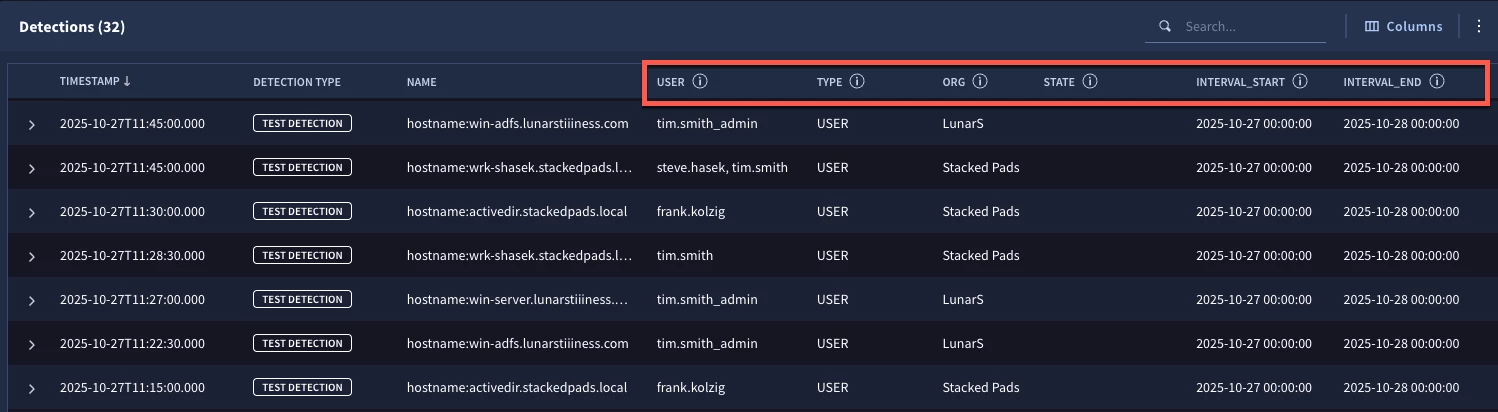
The absence of a value in state isn’t important here, but I do want to call out the two columns on the far right which are interval_start and interval_end. The detection was tested on October 27, 2025 and the data range for the entity is represented within those interval values. If we ran this rule on another date and the entity graph data was different on that date, the information for that data range would be represented here instead.
Appending a Data Table to the Entity Graph in our Rule
This time, we have made two changes to the previous rule. The first is that we have added a setup section to our rule. The setup section always goes after the meta section and before the events section. Remember we are creating an ephemeral version of the entity graph so we need to assemble that version before we can start applying logic to it within the rest of the rule!
rule process_launch_graph_append {
meta:
author = "Google Cloud Security"
description = "Detect process launch events and how the entity graph can be used with data tables to enrich a rule with Data Table Append."
type = "detection"
data_source = "sysmon"
platform = "Windows"
severity = "Info"
priority = "Info"
setup:
graph_append [$graph, %append_user_list]
events:
$process.metadata.event_type = "PROCESS_LAUNCH"
$process.principal.user.userid != ""
$process.principal.user.userid != /\$$/
$process.principal.user.userid != "admin"
$process.principal.user.userid = $userid
$process.principal.hostname = $hostname
$graph.graph.metadata.entity_type = "USER"
$graph.graph.metadata.source_type = "ENTITY_CONTEXT"
$graph.graph.entity.user.userid = $userid
match:
$hostname over 15m
outcome:
$user = array_distinct($graph.graph.entity.user.userid)
$type = array_distinct($graph.graph.metadata.entity_type)
$org = array_distinct($graph.graph.entity.user.company_name)
$state = array_distinct($graph.graph.entity.user.office_address.state)
$interval_start = array_distinct(timestamp.get_timestamp($graph.graph.metadata.interval.start_time.seconds))
$interval_end = array_distinct(timestamp.get_timestamp($graph.graph.metadata.interval.end_time.seconds))
$probationary = array_distinct($graph.graph.additional.fields["probationary"])
condition:
$process and $graph
}
The other change is that we added to the outcome section a variable called probationary. The entity graph did not contain this field, it only exists in the data table, but even though it isn’t mapped to the entity graph, it can still be used by using the column name from the data table as the key within the additional.fields portion of the schema.
When we test the rule, we have a lot to talk about! In blue, notice we have a detection for alice.young. Alice is part of the data table but is not part of my entity graph. So we can see the organization, state and interval time range and probationary value from the data table reflected in the detection. Notice the interval range is July 1, 2025 to December 31, 2026? That reflects the date range where this entry would be applicable for rules executed within that time range.
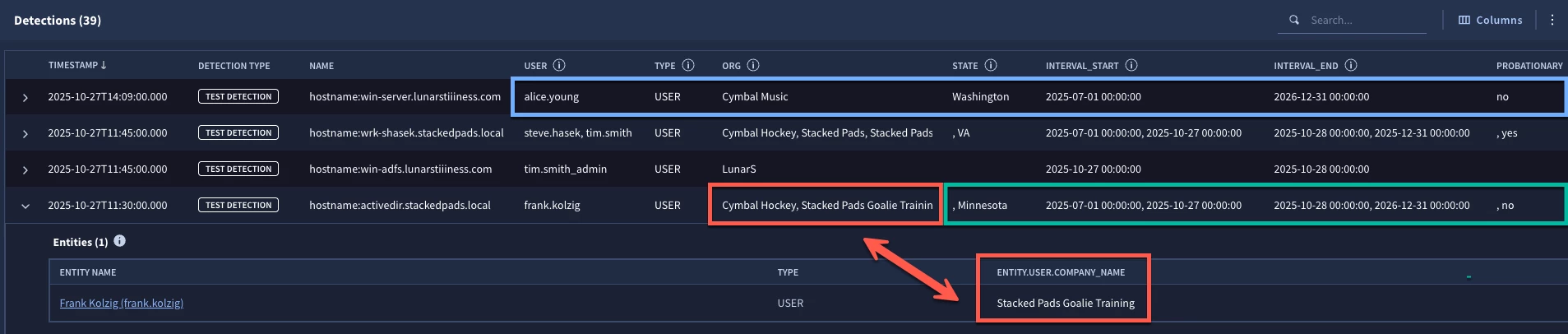
When we expand the detection that has a user of frank.kolzig, we also see something interesting. Notice we have expanded the detection and can see the entity and the company name in the entity graph is Stacked Pads Goalie Training. However, in the detection the org lists both this and Cymbal Hockey. The next two fields, state and probationary, are both returning an array of data, but the first value is a null, so state returns the value of , Minnesota and probationary returns , no. When we look at the interval_start and interval_end, we get two dates each. What’s going on?
This brings us to an important point about the graph_append command. When it is used, no deduplication of the rows appended to the entity graph will be performed. So, if a row is present in both the entity graph and the data table, both rows are present in the combined ephemeral entity graph view. Because we are using an array_distinct function in the outcome section, we are getting both values in the outcome section for org, state, probationary, and interval.
OK great, now I have an array with a null value and a non-null value in a few fields. Is there anything I can do about this?
The short answer is yes, though this is not a part of the graph_append, but another function. I probably should dedicate a post to this function, but for the moment this will do. In the outcome section, when we use the function array_distinct, our output is in an array_string (in this case) datatype which is what we see with , Minnesota and has , no in our detections. We can convert this outcome variable to a string and get rid of the null values in the array by prepending the function with arrays.join_string and then using a delimiter like a comma or whatever your delimiter of choice is.
In the example above, if I modify the state and probationary outcome variables like this:
$state = arrays.join_string(array_distinct($graph.graph.entity.user.office_address.state),",")
$probationary = arrays.join_string(array_distinct($graph.graph.additional.fields["probationary"]),",")
The output is now a string and the null values in the array are gone.

One final point that I would like to call out. When we added the entity graph to the rule, we used the following criteria to the rule.
$graph.graph.metadata.entity_type = "USER"
$graph.graph.metadata.source_type = "ENTITY_CONTEXT"
This caused a reduction in the amount of entity data that needed to be scanned for the join to take place between the entity graph and the event, making the rule run faster. When we brought the data table to be appended to the entity graph, because we had these two fields already prepped and in the data table, our rule ran flawlessly. If we had not defined them in the data table, the data table would have still been appended but the criteria would not have been met because those fields didn’t exist and our data table values would not have met the rule conditions and would have been excluded. This is why a little pre-planning around data preparation can pay large dividends when appending data tables and the entity graph to one another!
I hate to make a long blog even longer, but we are in the home stretch here so stick with me! The graph_append command is probably the most used and desired of the three data table and entity graph commands because it can flexibly create a superset of entity graph data by leveraging the dynamic nature of a data table.
Here are a few tips to remember:
- The data table must include columns to validate the entity that maps to metadata.interval.start_time.seconds and metadata.interval.end_time.seconds
- This means that interval times in the data table should be a primary troubleshooting point
- Filters specified in the rule are applied after appending the data table and the entity graph
- If the rule uses filtering terms like $graph.graph.metadata.entity_type = "USER" and $graph.graph.metadata.source_type = "ENTITY_CONTEXT", these values must be reflected in the data table
- If an entity exists in both the data table and the entity graph, it is possible to have a duplicate
I realize I just gave you a lot of information here but I hope you build a data table, append it to the entity graph and give this a try. Remember, while my example used user entity data, there is no reason you can’t use other entities and this might be a quick and easy win when it comes to applying additional threat intel indicators to your rule sets, especially for fast moving threats where you need to apply indicators immediately to your detection logic. If you want to see that use case in action, respond back in the comment section of the blog or shoot me a note and I will write that one up and share it!


