Hi all,
I'm looking for some clarity around the use and interpretation of the metadata.log_type and metadata.base_labels.log_types fields in Google SecOps / Chronicle UDM, particularly in relation to the log ingestion method and parser behaviour.
The Standard Flow:
When data (e.g., Windows Event Logs) is ingested via agents like BindPlane, Chronicle automatically detects the log source (e.g., WINEVTLOG) and uses the appropriate parser – in this case, Windows Event Parser. The parsed UDM ends up with fields such as:
"metadata": {
"logType": "WINEVTLOG",
...
"baseLabels": {
"logTypes": ["WINEVTLOG"]
}
}
This makes sense – the original raw event (XML) is parsed and normalized, and the parser used is reflected here.
My Question:
When I take a pre-parsed UDM log (in the same format as above), and upload it manually via the Events Import API, the fields instead show:
"metadata": {
"logType": "UDM",
...
"baseLabels": {
"logTypes": ["UDM"]
}
}
This behavior is expected, I suppose, since the import endpoint is for UDM-format data – but it leads to some questions:
Core Questions:
-
Is
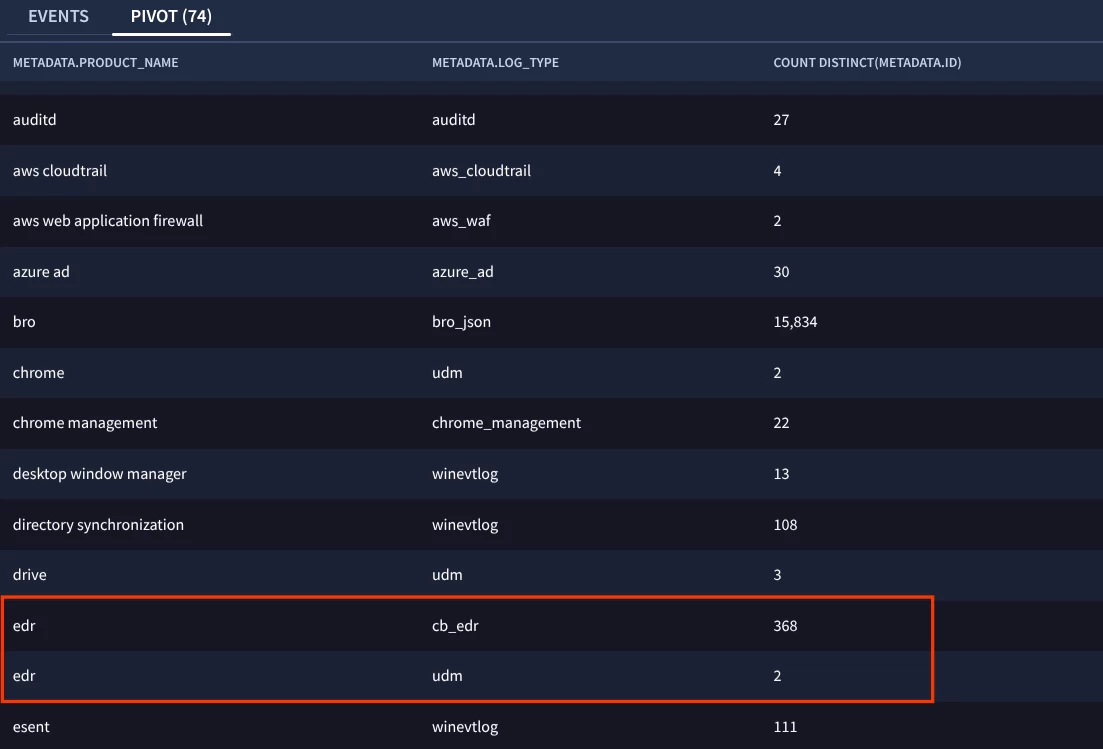
metadata.log_typesimply an indicator of the ingestion parser used (e.g., WINEVTLOG, UDM, etc.), or is it meant to semantically represent the original log source type? -
If the field only reflects how the log was ingested (e.g., RAW → parsed by SecOps vs. UDM → imported), does that mean it should not be used in detection logic to identify log types?
-
Is there a way to preserve or explicitly declare the original source (e.g., WINEVTLOG) when uploading via the UDM import API, or is this strictly inferred by the system based on ingestion path?
It feels like once a raw log is parsed into UDM, it is technically no longer a WINEVTLOG – yet Chronicle still preserves that original log type in the metadata. However, when I manually upload UDM, I'm unable to specify the original type, and the logType defaults to UDM.
This raises concerns about the reliability of logType for detection logic – especially when mixing logs ingested both through automatic pipelines and via manual upload.
Would appreciate any insights or confirmation from others who've worked through this nuance!