I'm trying to extract ip and hostname from a nested json. There are multiple ips and hostnames depending on the alert category. How can we extract and assign all the IPs and hostnames it to target.ip and target.hostname?
I tokenized the IPs/Hostnames separately. It is doable but a bit complex when the keys are double-repeated like this.
However target.hostname has a single value unlike the target.IP . Do you need all the 2 IPs/Hostnames to be in a single event so should I go ahead and map the 2 hostnames to another repeated field like target.labels ? or is it ok to split the log entry into multiple separate events ?
I tokenized the IPs/Hostnames separately. It is doable but a bit complex when the keys are double-repeated like this.
However target.hostname has a single value unlike the target.IP . Do you need all the 2 IPs/Hostnames to be in a single event so should I go ahead and map the 2 hostnames to another repeated field like target.labels ? or is it ok to split the log entry into multiple separate events ?
i.e. This mapping below is more consistent, however looking at the type of logs you are trying to ingest I feel it would fit more in the asset context logs not the event ones ;
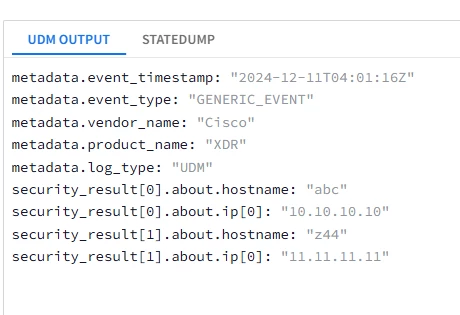
Hi @AbdElHafez Many Thanks for the detailed post. We are getting alerts from a external system and this particular part in json contains the ip/hostname of the machines which are affected. It can range from 1 to 30+. So, we thought to map it to "target" namespace.
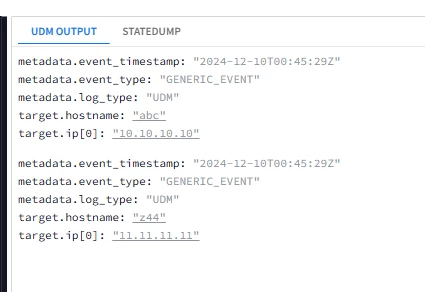
When I tested with the config you have provided, it's extracting the same way as you provided in your screenshot. Since it is having timestamp assigned for each extraction. When I validate the parser, it is giving 1000+ events against ingested events of 100 due to individual time stamp assignment.
So, I simplifed like below,
for k,v in target.data map { for k1,v2 in v.device map { if [v2][type] == "ip" { mutate {replace => {"ip" => "%{v2.value}"}} mutate {merge => {"event1.idm.read_only_udm.target.ip" => "ip"}} } if [v2][type] == "hostname"{ mutate {replace => {"host" => "%{v2.value}"}} mutate {rename => {"v2.value" => "event1.idm.read_only_udm.target.hostname"}} } } }
It's extracting the IP's with target.ip[0]/target.ip[1] and so on but the hostname is getting failed to parse.
Hi @AbdElHafez Many Thanks for the detailed post. We are getting alerts from a external system and this particular part in json contains the ip/hostname of the machines which are affected. It can range from 1 to 30+. So, we thought to map it to "target" namespace.
When I tested with the config you have provided, it's extracting the same way as you provided in your screenshot. Since it is having timestamp assigned for each extraction. When I validate the parser, it is giving 1000+ events against ingested events of 100 due to individual time stamp assignment.
So, I simplifed like below,
for k,v in target.data map { for k1,v2 in v.device map { if [v2][type] == "ip" { mutate {replace => {"ip" => "%{v2.value}"}} mutate {merge => {"event1.idm.read_only_udm.target.ip" => "ip"}} } if [v2][type] == "hostname"{ mutate {replace => {"host" => "%{v2.value}"}} mutate {rename => {"v2.value" => "event1.idm.read_only_udm.target.hostname"}} } } }
It's extracting the IP's with target.ip[0]/target.ip[1] and so on but the hostname is getting failed to parse.
That is because target.hostname is a unique field unlike target.ip which is repeated that is why I changed the parser to generate an event per host.
ou would need to pick a different field for the hostnames like in the about.labels for example or something similar to parse them. If you could pick which fields to be used for the hostnames then I could change the mapping back to 1 event per entry.
Using about.labels would be a correct call I guess @AbdElHafez
Hi @Aswin_Asokan, Note that 'labels fields for UDM nouns' (which includes 'about.labels') was deprecated on November 29, 2024[1]. It is recommended to use 'additional.fields'.
Using about.labels would be a correct call I guess @AbdElHafez
@Aswin_Asokan Could you give some more context about the type of the datasource and use case for the events ? As @AymanC indicated true it seems the about labels may not be a sustainable choice in the future. But I am trying to figure out if these logs are better off as asset context that could be used for enriching other events, or UDM events ? and figure out a proper mapping for the hostnames field.