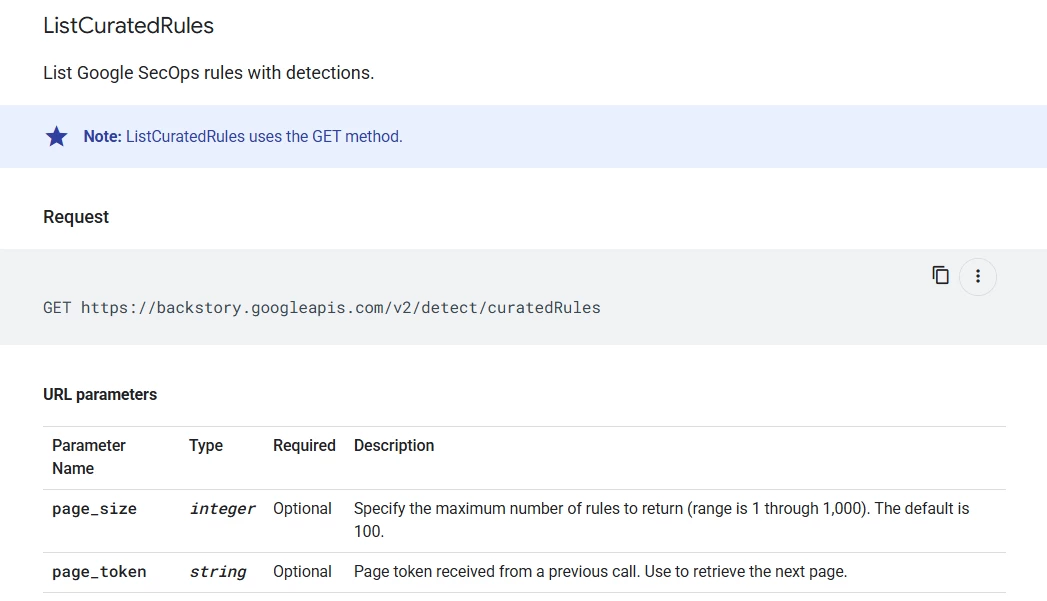
I’ve been trying to export a list of curated rules using the Chronicle API. I attempted both the legacy Backstory endpoint and the newer Chronicle API.
When using the Backstory endpoint, I receive a 403 error indicating that the Backstory API isn't enabled. However, I’m unable to locate the Backstory API in the SecOps GCP project - only the Chronicle API appears to be available which is already enabled.
On the other hand, when I use the Chronicle API and try to use the curatedrules.list method, I receive a 404 error stating that the endpoint doesn't exist. I'm confident the {parent} parameter is valid, as I’ve successfully used it to export custom rules from the same SecOps tenant.
I’m using a service account with keys and the official api-samples-python scripts to retrieve the rule list.