Hi all,
I'm currently working on a custom Chronicle parser using Logstash to handle logs in CEF format. I have already built and tested a parser for CEF logs that include key-value pairs these work correctly and generate UDM events as expected.
While parsing these non-KV logs, no UDM events or entities are generated in Chronicle is what I am getting.
Format 1 which is paring: <priority>CEF:0|vendor|product|version|signature|name|severity|key1=value1|key2=value2|…
Format 2 which is not generating UDM event and not parsing
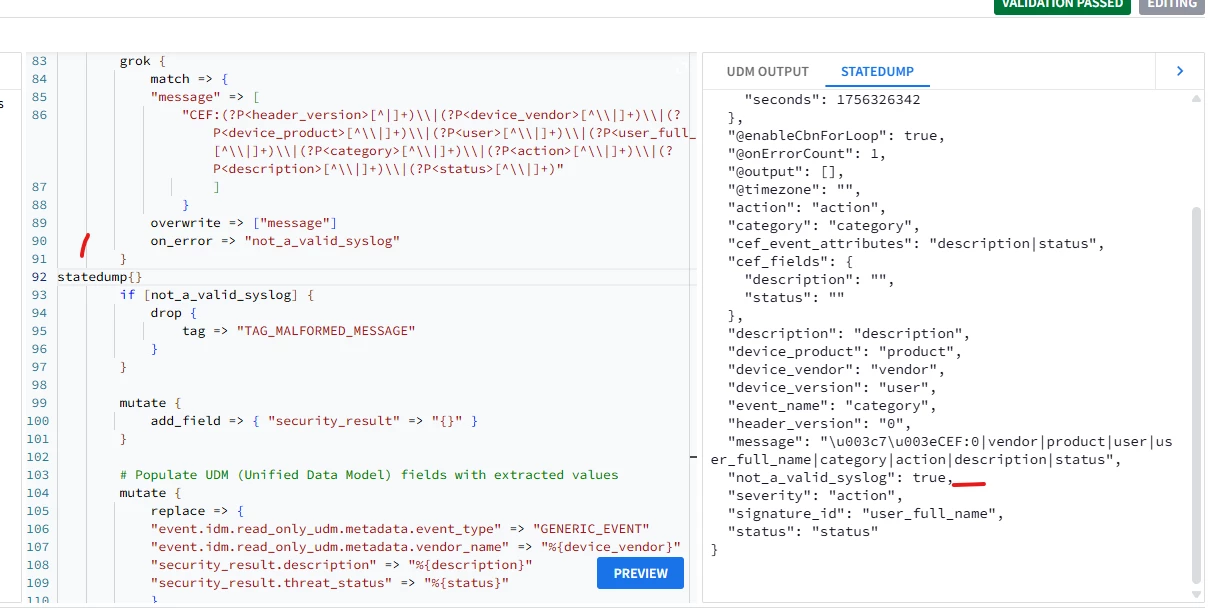
<priority>CEF:0|vendor|product|user|user_full_name|category|action|description|status
and for the format 2 I am getting
"No UDM events or entities were generated for the current parser configuration. If this is not intended, rectify the code snippet/UDM mappings and then click preview.”
filter {
grok {
match => {
"message" => [
"CEF:(?P<header_version>[^|]+)\\|(?P<device_vendor>[^\\|]+)\\|(?P<device_product>[^\\|]+)\\|(?P<device_version>[^\\|]+)\\|(?P<signature_id>[^\\|]+)\\|(?P<event_name>[^\\|]+)\\|(?P<severity>[^\\|]+)\\|%{GREEDYDATA:cef_event_attributes}"
]
}
overwrite => ["message"]
on_error => "not_a_valid_syslog"
}
if [not_a_valid_syslog] {
drop {
tag => "TAG_MALFORMED_MESSAGE"
}
}
kv {
source => "cef_event_attributes"
field_split => "|"
value_split => "="
target => "cef_fields"
}
if [cef_event_attributes] =~ "=" {
mutate {
replace => {
"cef_fields.status" => ""
"cef_fields.updatedOn" => ""
"cef_fields.createdOn" => ""
"cef_fields.src_hostname" => ""
"cef_fields.dst_hostname" => ""
}
}
mutate {
add_field => { "security_result" => "{}" }
}
if [cef_fields][status] != "" {
if [cef_fields][status] in ["CREATED", "IN_PROGRESS"] {
mutate {
replace => { "security_result.threat_status" => "ACTIVE" }
}
}
else if [cef_fields][status] == "RESOLVED" {
mutate {
replace => { "security_result.threat_status" => "CLEARED" }
}
}
else {
mutate {
replace => { "security_result.threat_status" => "THREAT_STATUS_UNSPECIFIED" }
}
}
}
# Populate UDM (Unified Data Model) fields with extracted values
mutate {
replace => {
"event.idm.read_only_udm.metadata.event_type" => "GENERIC_EVENT"
"event.idm.read_only_udm.metadata.vendor_name" => "%{device_vendor}"
"security_result.description" => "%{event_name}"
}
}
mutate {
merge => {
"event.idm.read_only_udm.security_result" => "security_result"
}
}
mutate {
merge => {
"@output" => "event"
}
}
}
else {
grok {
match => {
"message" => [
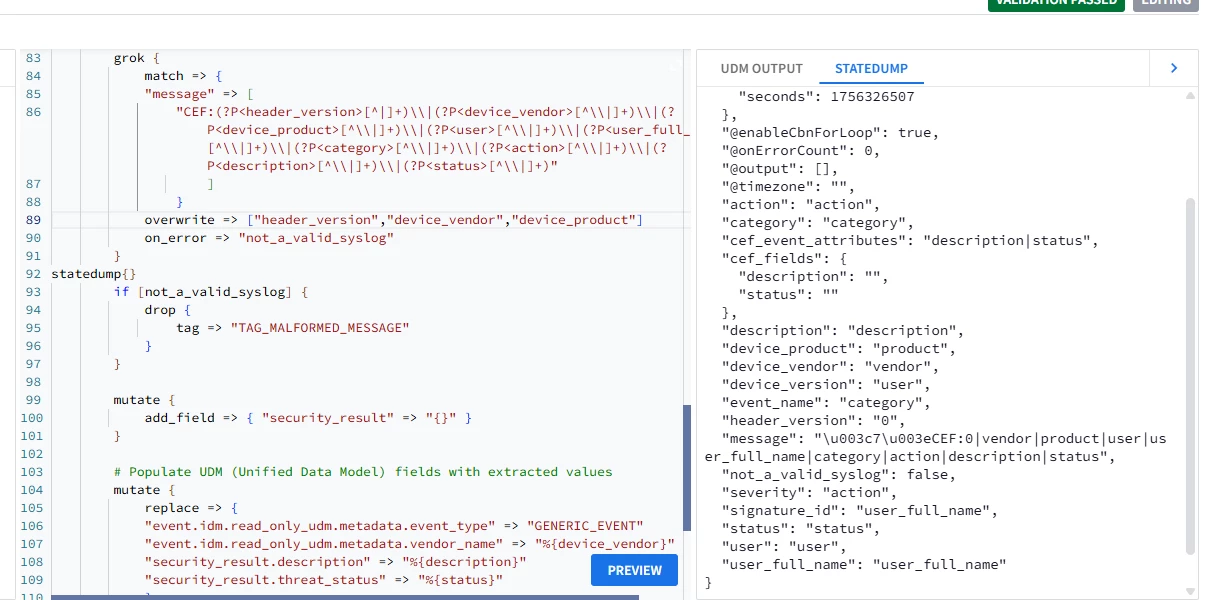
"CEF:(?P<header_version>[^|]+)\\|(?P<device_vendor>[^\\|]+)\\|(?P<device_product>[^\\|]+)\\|(?P<user>[^\\|]+)\\|(?P<user_full_name>[^\\|]+)\\|(?P<category>[^\\|]+)\\|(?P<action>[^\\|]+)\\|(?P<description>[^\\|]+)\\|(?P<status>[^\\|]+)"
]
}
overwrite => ["message"]
on_error => "not_a_valid_syslog"
}
if [not_a_valid_syslog] {
drop {
tag => "TAG_MALFORMED_MESSAGE"
}
}
mutate {
add_field => { "security_result" => "{}" }
}
# Populate UDM (Unified Data Model) fields with extracted values
mutate {
replace => {
"event.idm.read_only_udm.metadata.event_type" => "GENERIC_EVENT"
"event.idm.read_only_udm.metadata.vendor_name" => "%{device_vendor}"
"security_result.description" => "%{description}"
"security_result.threat_status" => "%{status}"
}
}
mutate {
merge => {
"event.idm.read_only_udm.security_result" => "security_result"
}
}
mutate {
merge => {
"@output" => "event"
}
}
}
}
Any guidance or suggestions on how to properly support both CEF formats in the same parser would be appreciated.