I am trying to create a dashboard to visualize data, comparing a custom CIDR data table with a large amount of entries (~5k) to our logs. I am using net.ip_in_range_cidr to compare entries in the data table with log IP addresses.
Other than filtering on log types or other fields, how else can I get better performance and avoid time complexity issues when running different queries?
Best answer by AbdElHafez
@momentobear depending on the architecture and tools you have.
1. If you are using the traditional Class-based subnetting you could do something like this for a sample log ;
You could use a search like this , you will get definitely results even for your existing resources
If you are using classless routing -which is most probably- , you can still do the same but your regex patterns will be more complex.
You could use other solutions like add the field using NXLog at the source nodes if you are using it at the source Nix-like OS nodes, this is easier programmatically. Same for fluentbit used in GKE I think.
Alternatively enrichment through Cribl, or may be a similar functionality in Binplane, or do this even in the intermediate message queues like PubSub or Kafka using KQL or CloudFlow but these a will be problematic due to the large CIDR ranges you have and the complexity of the setup in that case.
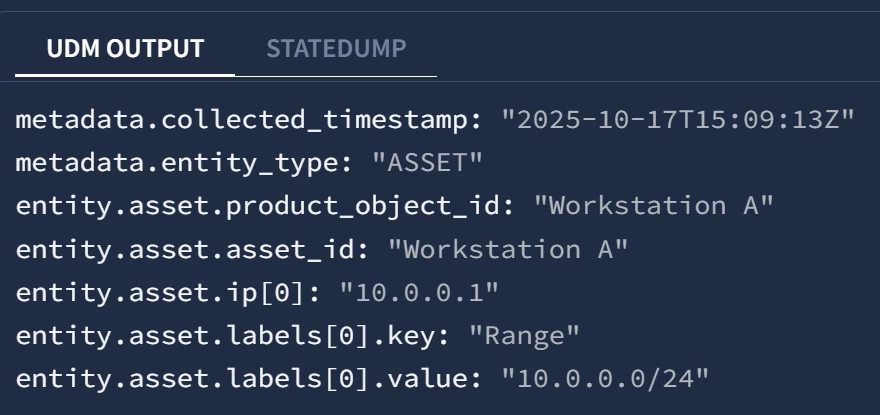
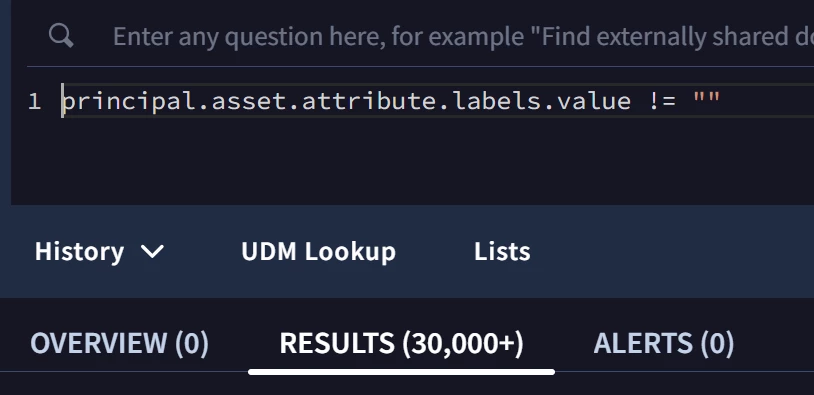
You could add them as IP Range entities, verify that the IPs will appear as entity attributes in the UDM fields, and then use the IP Range names instead of CIDRs for the filtering.
@momentobear if the enrichment is done properly, the IP Ranges will be marked with an enriched field in the graph. If you are visualizing a specific activity then you could build a rule without alerting for this activity and this rule will utilize the join between the graph and UDM events, and then build off your dashboard based on the detection.
If that is not exactly your use case or too cumbersome, could you share some more details about the scale of the logs or the type of comparison ?
You could use a search like this , you will get definitely results even for your existing resources
If you are using classless routing -which is most probably- , you can still do the same but your regex patterns will be more complex.
You could use other solutions like add the field using NXLog at the source nodes if you are using it at the source Nix-like OS nodes, this is easier programmatically. Same for fluentbit used in GKE I think.
Alternatively enrichment through Cribl, or may be a similar functionality in Binplane, or do this even in the intermediate message queues like PubSub or Kafka using KQL or CloudFlow but these a will be problematic due to the large CIDR ranges you have and the complexity of the setup in that case.
@AbdElHafez Thank you for the potential solutions. I’m thinking I will have to go with either 3 or 4. With 1 and 2 I have several parsers which would need to be maintained on top of the complexity in regex needed to accommodate the matches I’d be looking for.
Appreciate the assistance and engagement. Hopefully this helps others looking for a similar solution in the future.
@momentobear I hope my suggestions were useful. If that either 3-4 did not work, there are 2 other alternatives I thought about ;
Passing your Asset information with the range but as a fixed string to an entity context feed, i.e. For example add a field in CMDB programmatically to indicate the range for each registered IP, and ingest/parse this info in the entity context within the asset.attribute.labels field as indicated above.
{“asset_id” : “workstation1”, "Range": "Range A"}
The drawback is that you will have to do this for every single IP in the SIEM scope.
You could implement a hierarchical parser extension for the IP Ranges : ex: IF int(oct1) > x1 and < x2 THEN {Possible ranges are r1,r2,...rn ; IF int(oct2) > y1 and < y2 THEN {Possible ranges are r11,r12,...r1n} } ...etc. This is definitely still complex, but could be easier to handle than pure regex matches.