
I was checking out the following video on ordering events:
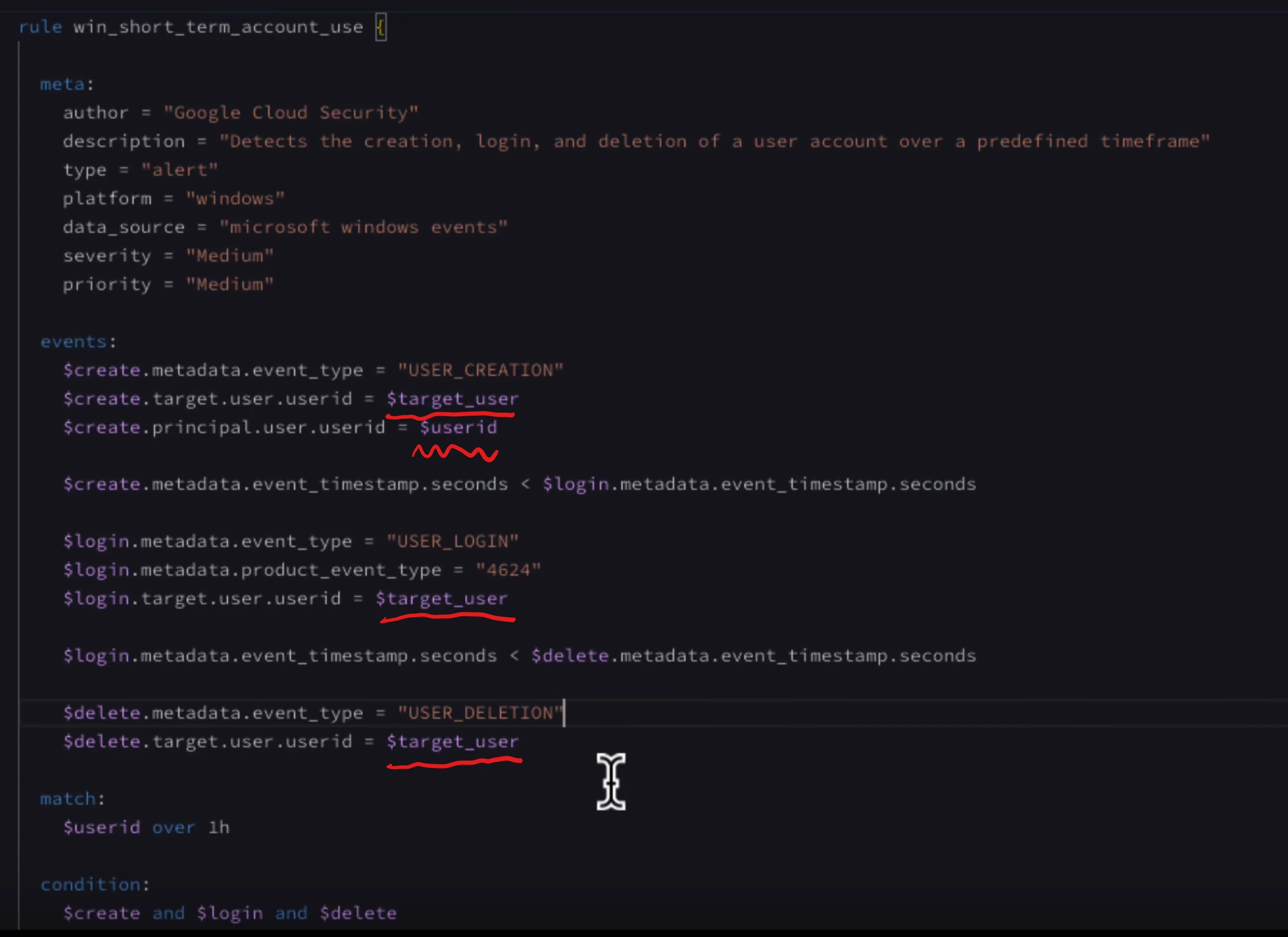
I am unable to understand what is the difference between `target.user.userid` and `principal.user.userid` fields?

 +8
+8I was checking out the following video on ordering events:
I am unable to understand what is the difference between `target.user.userid` and `principal.user.userid` fields?
Best answer by ion_
Similar to the message on your other thread, theres the idea in UDM of a Principal being the one acting and the Target being the one acted upon. In some instances this is clear and intuitive. However, I often find myself digging into the logs to understand how various fields have been filled in.
Does that help?
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.




