I've been wrestling with the correct syntax to calculate a risk score based on unique, not repeated, values across multiple logs.
For example, let's say there are several different discovery commands run on the command line of a single host over the course of five minutes such as ipconfig, whoami, and systeminfo; for this example let's also say that ipconfig is run twice in that five minute window.
Technically only three distinct commands have been run but if you use a sum aggregation (and let's say you give each one an arbitrary value of '5') then in this case the sum will be 20 instead of 15. Is there a way to calculate the risk score based solely on each unique occurrence of a command and not the total number of commands in the match window?
I know there is the array_distinct aggregation which would show only the three distinct commands but I cannot figure out how to incorporate that into a risk score and subsequently a condition statement.
Is this something that is even possible or am I needlessly beating my head against the wall?
Best answer by jstoner
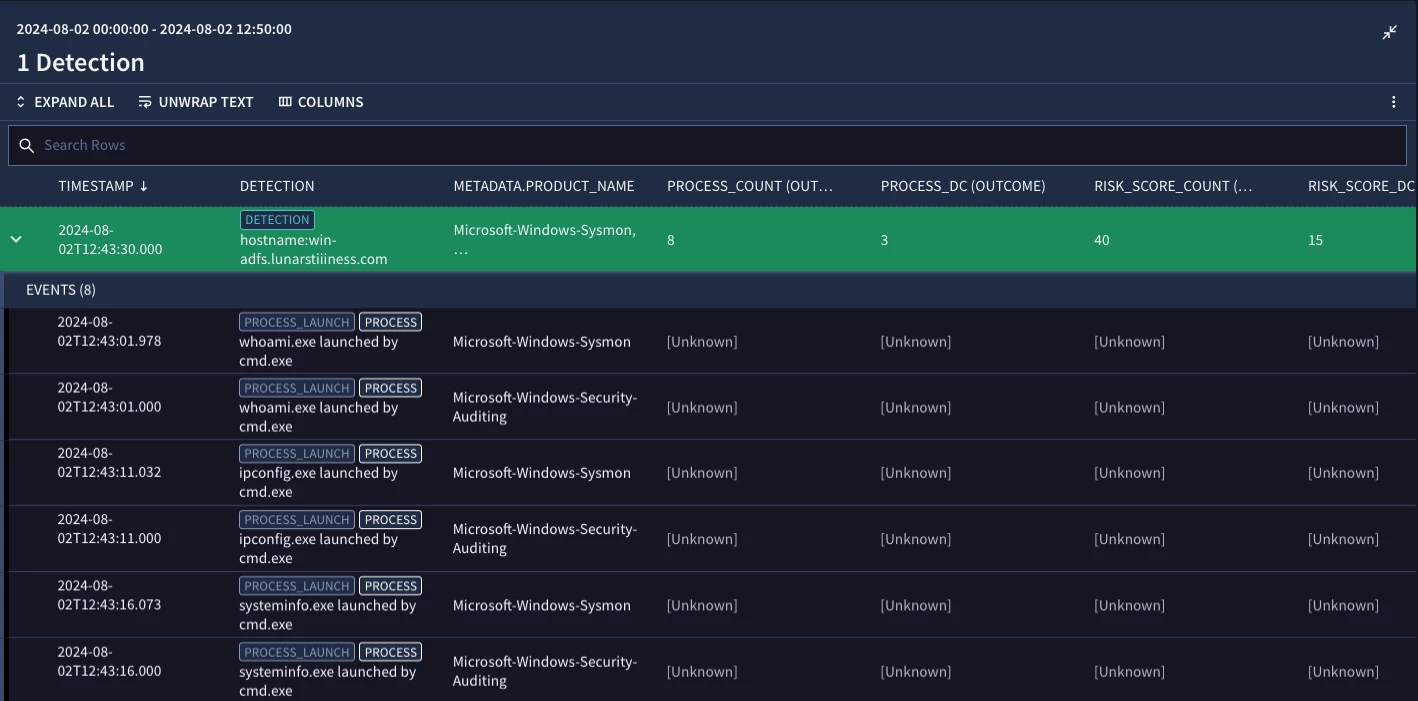
Based on what you described, this is how I would approach this, though there are likely other ways and additional complexity that might need to go into the risk score. In the example below, I generated two different counts, one is a count of the process command line value where we would see those commands and the other a count_distinct. From there, I calculated the risk scores, one using distinct count and the other using count.
rule risk_score_example {
meta:
author = "Google Cloud Security"
description = "Calculate a risk score based on the number of unique commands executed (08/02/24)"
severity = "Medium"
events:
$process.metadata.event_type = "PROCESS_LAUNCH"
$process.principal.hostname = $hostname
(
$process.target.process.command_line = /whoami/ nocase or
$process.target.process.command_line = /systeminfo/ nocase or
$process.target.process.command_line = /ipconfig/ nocase
)
match:
$hostname over 5m
outcome:
$process_count = count($process.target.process.command_line)
$process_dc = count_distinct($process.target.process.command_line)
$risk_score_count = $process_count * 5
$risk_score_dc = $process_dc * 5
condition:
$process
}
In my test results you can see that we have our detection and one risk score of 40 and the other of 15. I have the added issue of 2 different log sources for process launch so using count makes my number even more inflated but by using distinct count, we still have 3 unique process launches and therefore a risk value of 15.
Based on what you described, this is how I would approach this, though there are likely other ways and additional complexity that might need to go into the risk score. In the example below, I generated two different counts, one is a count of the process command line value where we would see those commands and the other a count_distinct. From there, I calculated the risk scores, one using distinct count and the other using count.
rule risk_score_example {
meta:
author = "Google Cloud Security"
description = "Calculate a risk score based on the number of unique commands executed (08/02/24)"
severity = "Medium"
events:
$process.metadata.event_type = "PROCESS_LAUNCH"
$process.principal.hostname = $hostname
(
$process.target.process.command_line = /whoami/ nocase or
$process.target.process.command_line = /systeminfo/ nocase or
$process.target.process.command_line = /ipconfig/ nocase
)
match:
$hostname over 5m
outcome:
$process_count = count($process.target.process.command_line)
$process_dc = count_distinct($process.target.process.command_line)
$risk_score_count = $process_count * 5
$risk_score_dc = $process_dc * 5
condition:
$process
}
In my test results you can see that we have our detection and one risk score of 40 and the other of 15. I have the added issue of 2 different log sources for process launch so using count makes my number even more inflated but by using distinct count, we still have 3 unique process launches and therefore a risk value of 15.
Based on what you described, this is how I would approach this, though there are likely other ways and additional complexity that might need to go into the risk score. In the example below, I generated two different counts, one is a count of the process command line value where we would see those commands and the other a count_distinct. From there, I calculated the risk scores, one using distinct count and the other using count.
rule risk_score_example {
meta:
author = "Google Cloud Security"
description = "Calculate a risk score based on the number of unique commands executed (08/02/24)"
severity = "Medium"
events:
$process.metadata.event_type = "PROCESS_LAUNCH"
$process.principal.hostname = $hostname
(
$process.target.process.command_line = /whoami/ nocase or
$process.target.process.command_line = /systeminfo/ nocase or
$process.target.process.command_line = /ipconfig/ nocase
)
match:
$hostname over 5m
outcome:
$process_count = count($process.target.process.command_line)
$process_dc = count_distinct($process.target.process.command_line)
$risk_score_count = $process_count * 5
$risk_score_dc = $process_dc * 5
condition:
$process
}
In my test results you can see that we have our detection and one risk score of 40 and the other of 15. I have the added issue of 2 different log sources for process launch so using count makes my number even more inflated but by using distinct count, we still have 3 unique process launches and therefore a risk value of 15.
Hope this is what you were looking for!
I think that actually works for me. I am still fiddling with the regex to match all of the possible discovery commands that I'm looking for but the distinct count seems to do what I need if I include that as a condition.