
Author: Ivan Ninichuck
Co-author: Oleg Siminel

Introduction
This is a guide to adopting standardized data and incident handling practices within a SecOps (Security Operations) product. It emphasizes the importance of aligning security practices with core business objectives, focusing on threat detection, response orchestration, and continuous improvement. The guide also details the practical application of these principles, offering step-by-step instructions for data ingestion, security analytics, and response automation. By implementing these strategies, organizations can establish a proactive and resilient security posture, effectively mitigating cyber threats and safeguarding critical assets.
Core First Principle of Cyber Security
The starting point for creating a use case is the Core First Principle of Cyber Security. The definition of this principle is “ to reduce the probability of material impact from a Cyber Attack”. This definition was developed by Rick Howard (Howard, Rick Cyber Security First Principles 2023). He developed this definition after years of experience in the industry including his time in the army as the Commander of the Army's Computer Emergency Response Team (CERT). Building from this definition are a set of strategies that fit the core principles that are foundational.
Core Principle Strategies
Zero Trust: A security framework built on the principle of "never trust, always verify." It assumes that no user or device, whether internal or external, can be trusted by default. Every access request, regardless of its origin, is subject to strict verification and authorization. This approach eliminates the traditional security perimeter and enforces security checks at every level, making it significantly harder for attackers to move laterally within a network once they gain initial access.
Intrusion Chain Prevention: A proactive defense strategy that focuses on disrupting the sequence of steps (the "chain") that attackers typically follow to achieve their goals. Rather than simply blocking individual attacks, this approach aims to understand and disrupt the attacker's tactics, techniques, and procedures (TTPs) at each stage of the attack lifecycle. This can involve a combination of preventive controls (e.g., blocking known malicious activity), detective controls (e.g., identifying suspicious behavior), and disruptive controls (e.g., deceiving or misdirecting the attacker).
Resilience: The ability of a system, network, or organization to withstand and recover quickly from security incidents, disruptions, or other adverse events. This involves building systems that are not only resistant to attacks but also capable of adapting to changing threats and maintaining essential functions even in the face of a compromise. Resilience strategies often include redundancy, failover mechanisms, data backups, and incident response plans.
Risk Forecasting: A proactive approach to risk management that involves predicting potential threats and vulnerabilities based on current trends, historical data, and emerging technologies. By anticipating future security risks, organizations can take preemptive measures to mitigate them before they materialize. This can involve threat intelligence analysis, vulnerability scanning, and scenario planning.
Automation: The use of technology to automate repetitive, time-consuming, or complex security tasks. This can include threat detection and response, vulnerability management, incident response, and compliance monitoring. Automation can improve efficiency, reduce human error, and enable security teams to focus on more strategic initiatives. However, it is important to implement automation carefully to avoid unintended consequences or creating new vulnerabilities.
Continuous Detection & Continuous Response
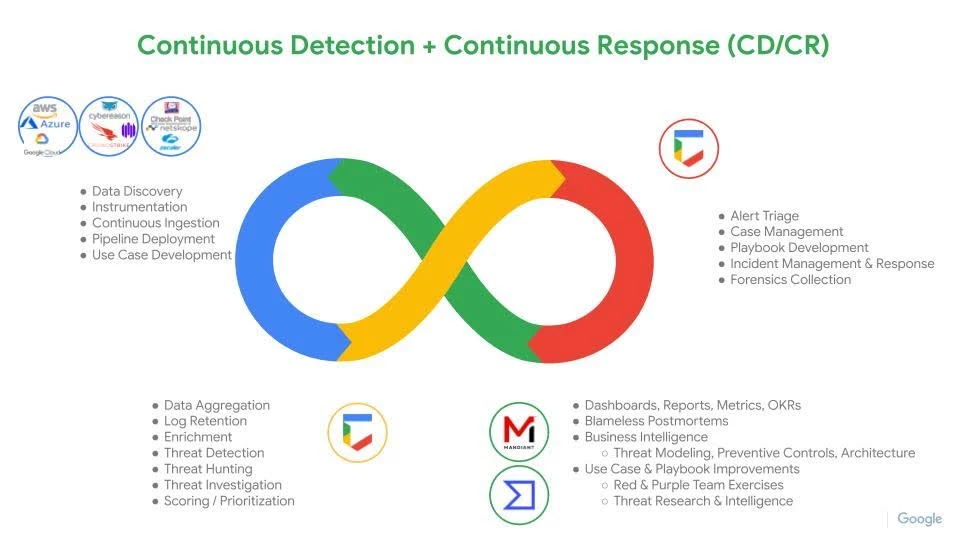
When developing a use case the continuous detection/continuous response workflow is employed. Following the four phases of data visibility, security analytics, response orchestration and Continuous feedback the entire cycle of use case development can be planned and executed. More importantly the cycle can iterate multiple times as the use case evolves and matures.
Data Visibility
The initial phase of establishing robust security operations encompasses a multifaceted approach that begins with a thorough asset evaluation. This involves identifying and cataloging all critical assets within an organization's infrastructure, including hardware, software, data, and personnel.
Subsequently, threat modeling is conducted to identify potential threats and vulnerabilities that could compromise these assets. By understanding the threat landscape, organizations can proactively implement measures to mitigate risks.
Data source identification is another crucial step in this phase. This involves identifying all relevant data sources that can provide insights into security events and incidents. These data sources may include logs, network traffic, and endpoint activity.
Effective log and analytics planning is essential for collecting, storing, and analyzing security data. This involves determining which logs to collect, how to store them, and which analytics tools to use.
Clear role definition ensures that everyone within the security operations team understands their responsibilities and how they contribute to the overall security posture.
Communication planning establishes protocols for communicating security events and incidents within the team and with other stakeholders. This includes defining escalation procedures and establishing communication channels.
A well-defined reporting framework enables the security operations team to track and report on key security metrics. This information can be used to identify trends, measure progress, and demonstrate the value of security operations.
By taking these comprehensive steps, organizations can establish a strong foundation for their security operations. This foundation provides comprehensive visibility into the security posture, enables clear communication between team members and stakeholders, and ensures alignment between security operations and overall business objectives.
This proactive approach not only supports ongoing security efforts but also enables effective incident response when security events occur. By having a well-defined plan in place, organizations can respond quickly and efficiently to security incidents, minimizing their impact and ensuring business continuity.
Security Analytics
Security Analytics is a crucial phase in the realm of cybersecurity. It involves systematically mapping established data sources to applicable techniques and generating corresponding detections. The ATT&CK framework provides invaluable Data Sources, each with specific components detailing adversarial actions. These components enable security teams to prioritize techniques based on the specific assets involved.
Threat hunting objectives, derived from these techniques, can be executed either in-house or by a managed service. The hunt hypothesis is formulated based on the techniques used against a particular data source, providing hunters with a deeper understanding of their objectives and potential threats.
The Security Operations phase encompasses incident response, digital forensics, and threat intelligence, all aimed at preventing future incidents. Throughout these stages, it is imperative to establish key performance indicators (KPIs) and metrics that measure the effectiveness of security activities and their alignment with business objectives. These metrics provide valuable insights into the success of security initiatives and their contribution to overall business goals.
Response Orchestration
Asset evaluation and threat modeling are crucial initial steps in establishing a robust security posture. By thoroughly assessing the value of assets and identifying potential threats, organizations can determine the specific data sources, logs, and analytics necessary for effective monitoring and protection. This process also plays a pivotal role in clarifying the objectives of SecOps teams and aligning them with overall business needs. By defining these goals, organizations can establish the roles and responsibilities required to achieve them, ensuring that all team members understand their part in maintaining security.
Moreover, clear communication procedures and reporting goals should be established between the teams responsible for managing these assets. Regular communication and collaboration are essential for ensuring that everyone is aware of potential threats and vulnerabilities and that they are working together to address them. This includes establishing protocols for reporting security incidents and ensuring that all team members know who to contact in the event of a breach. By fostering a culture of collaboration and communication, organizations can create a more effective and responsive security infrastructure.
Continuous Feedback
The feedback loop in the realm of security operations encompasses a multifaceted approach that integrates threat intelligence, operational enhancements, and strategic alignment to bolster an organization's defense mechanisms. The continuous refinement of detection rules, informed by insights gleaned from the local environment, coupled with tactical improvements in operational procedures, ensures that an organization remains agile and adaptive in the face of evolving threats. Furthermore, the integration of strategic business objectives into the feedback loop guarantees that security operations are not conducted in isolation, but rather, are intrinsically linked to the overarching goals of the organization.
This feedback loop manifests itself in various forms, contingent upon the nature of the information and the target audience. It serves as a catalyst for advanced security programs, such as purple teaming, where offensive and defensive teams collaborate to simulate real-world attack scenarios and evaluate the effectiveness of existing security controls. Additionally, the feedback loop plays a pivotal role in prioritizing technology investments, ensuring that resources are allocated to areas that yield the maximum return on investment in terms of security posture.
Moreover, the feedback loop drives the continuous improvement of internal procedures, fostering a culture of operational excellence within the security operations center. By providing executive leadership with a comprehensive and actionable overview of the threat landscape, the feedback loop empowers them to make informed decisions and develop proactive risk management strategies.
The cyclical nature of the feedback loop ensures that the lessons learned and insights gained are not merely ephemeral, but rather, are integrated into the subsequent iterations of the security operations workflow. This iterative process of continuous improvement guarantees that an organization's security operations remain dynamic, resilient, and aligned with the ever-changing threat landscape.
Practical Application: Data Visibility
- Utilize Google Threat Intelligence to create Threat Profile
- Map potential ATT&CK Techniques to Data Sources
- Discovery sessions to analyze specific environment
- Implement Data Ingestion Pipeline
Creating a Threat Profile

If you are a Google TI or Enterprise+ customer, you can leverage the threat profile module to enhance your mapping further. The threat profile creator in Google Threat intelligence(GTI) is the first step in creating a Use Case, or when iterating a new version. Remember the created profile will update over time as threat evolves. Don’t think of the threat profile as a static report but as a living document. The creation process requires the selection of an industry focus as well as a geographical region. Mandiant annual intelligence reports have consistently found these two variables to be the determining factors of what TTPs an organization is most likely to find adversaries use during attacks.
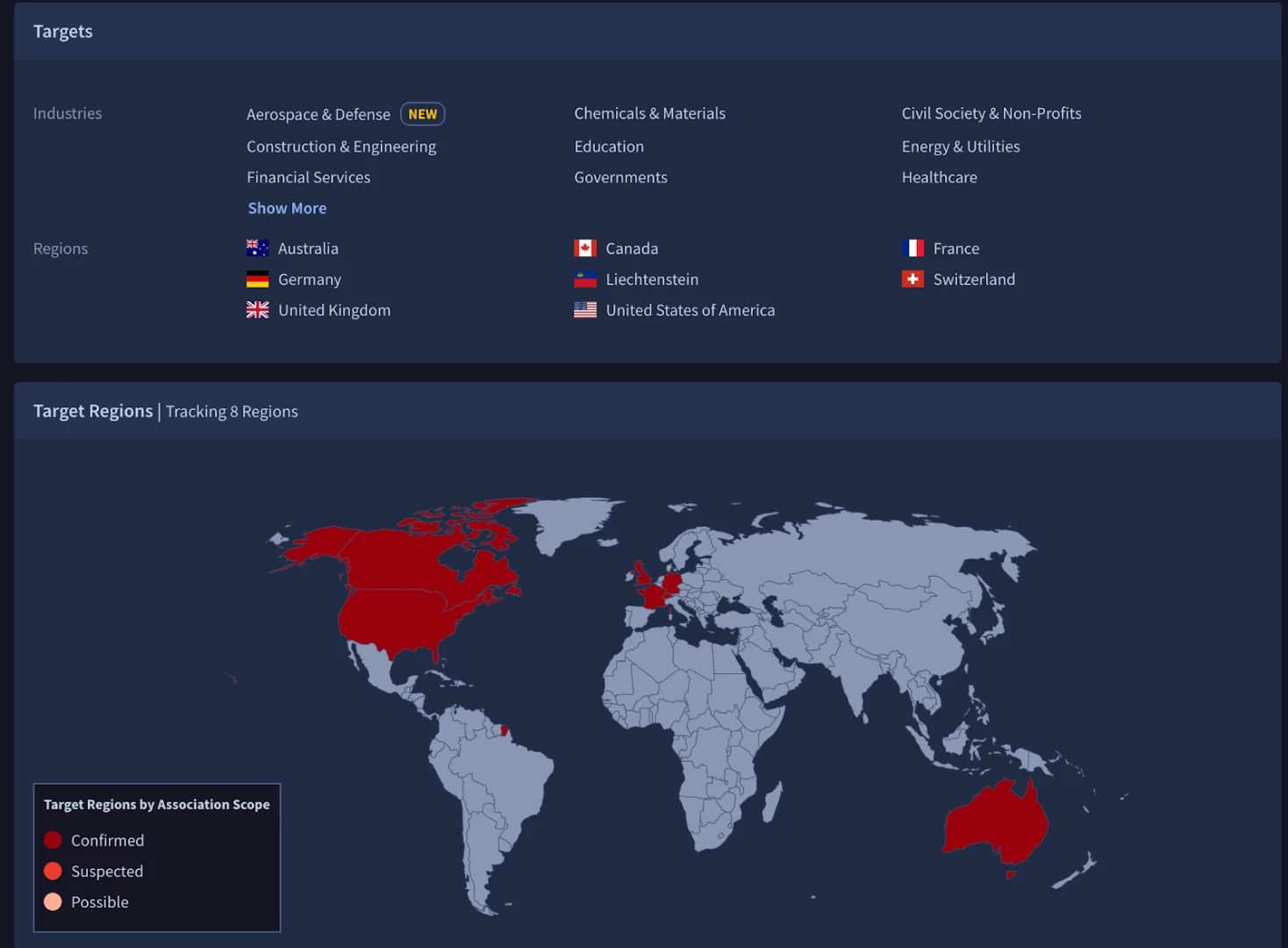
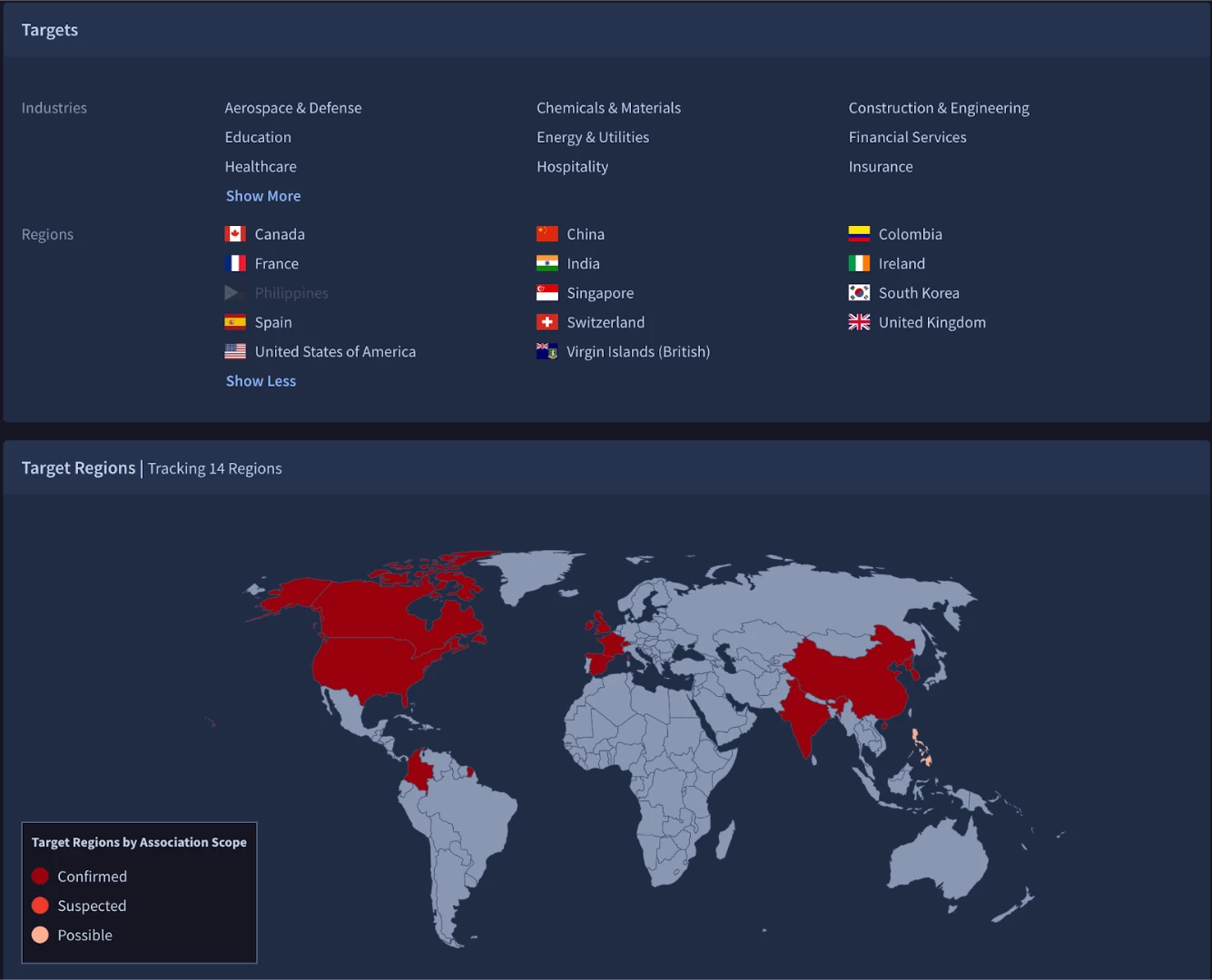
Based on the threat profile we have chosen the most relevant and recent threat actors as a starting point. Here we have the visuals for the targets for each threat group. The geography for our profile is Canada with Aerospace as the industry. There are two things that pop out right away. First, FIN6 covers a lot more geography than UNC 2565. This is not necessarily a bad thing, as FIN6 has been observed since 2014, but it is something to consider when trying to come up with a more focused list of TTPs. The item that really catches the eye is that UNC2565 has a “new” label listed by our industry chosen as a focus, Aerospace. This could indicate that this threat group is still expanding its targets on a much more accelerated basis and so might be a more pressing threat.
Researching the adversary
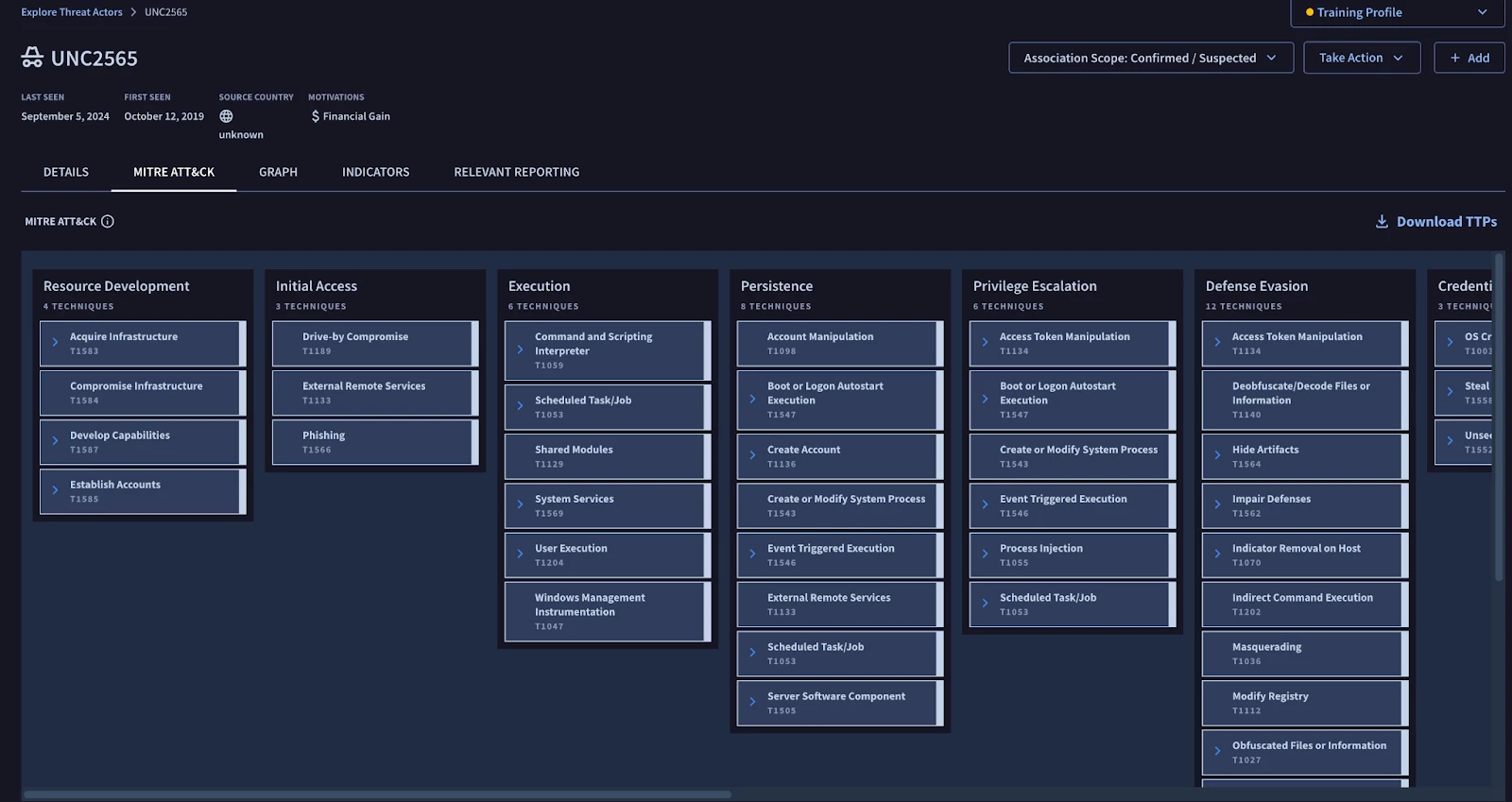
The MITRE ATT&CK tab is a valuable resource in this context, as it provides detailed information about the Techniques and Sub-Techniques employed by specific threat groups. These TTPs (Tactics, Techniques, and Procedures) can serve as a foundational starting point for developing initial use cases for further deployment.
During the discovery phase, this information is particularly beneficial for users, enabling them to establish connections between observed TTPs and potential threats. By understanding these relationships, users can gain valuable insights into how these threats might impact their most critical assets. This knowledge empowers them to prioritize their defense strategies and allocate resources effectively to protect their most valuable resources.
Connecting Techniques to Data sources
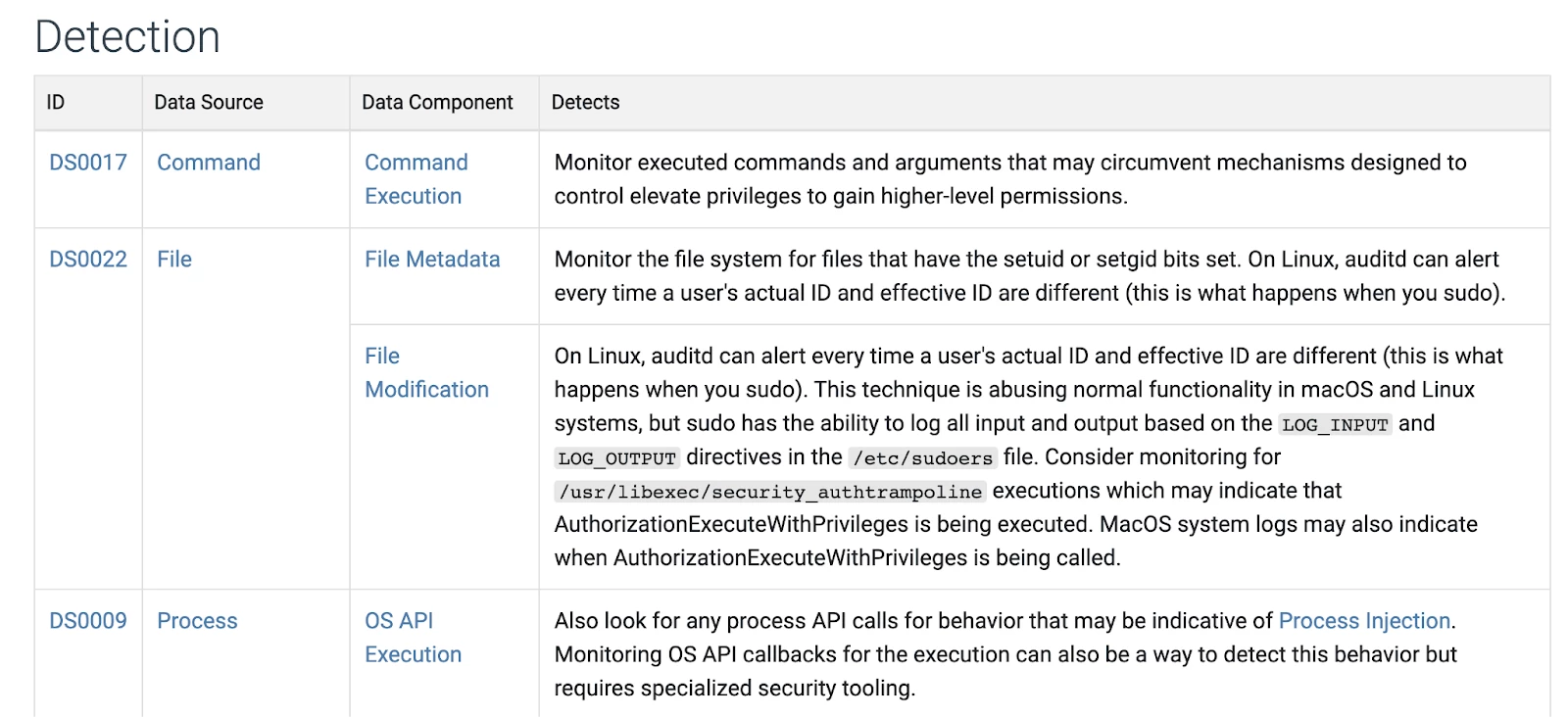
When you use the MITRE ATT&CK Website you can select individual techniques and they will have a section at the bottom called detection. In the image from this section you can see that the data source and data component for the technique is provided. You can access this information under the defenses tab of the website and look for techniques when you know the data source/data component. This provides you the ability to map in either direction. Currently we have some generalized Data Source mapping for the MVP Use Cases that are general templates to start off in onboarding. Usually the data source mappings in these templates will cover large umbrella use cases. For example with the UNC 2565 techniques we saw in the previous slide the Endpoint, Identity and Network MVP mappings would suffice. You should only have to map something more specifically when a use case is highly specialized to cover a smaller amount of TTPs.
Asset Discussion
The next step to getting the CIRs for data visibility will be part of your initial discovery regarding key assets. You will need to investigate to find out the environment specific information that is needed to evaluate use case development. Below are some of the questions that might be used. This is not an exhaustive list. The main objective is to use the experience of the organization to identify possible adversary focuses that a general threat profile cannot surface. For example knowing how users connect and how identity is managed narrows down quite a few generic techniques relating to those topics.
- How do assets key their business objectives
- What do you believe are their most important assets
- Determine where key assets are located(on-prem/Cloud/hybrid)
- How are users connecting to business environment
- What monitoring methods are you using currently
- How do you manage identity
- How are responsibilities for security and management of key assets divided in the organization
Implementing Ingestion Pipeline
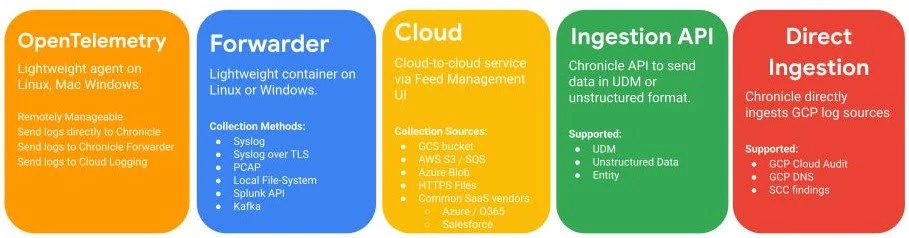
Google SecOps has many choices on how data can be ingested. The method for a particular source is mainly decided by what type of log or telemetry is being ingested. The image above shows the recommended ingestion methods for common log sources. In the platform itself you are able to manage these ingestion methods in the SIEM settings panel.
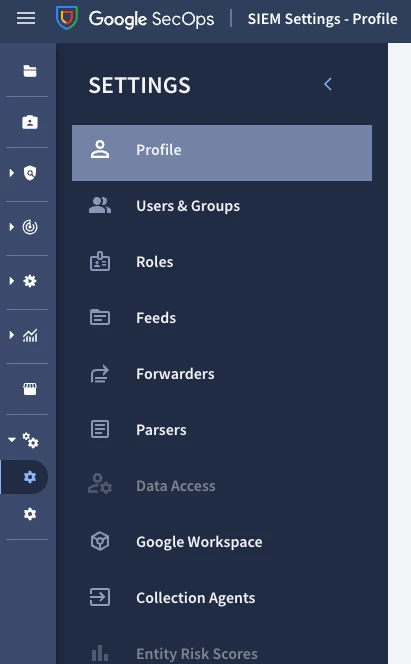
The settings panel has three main sections where ingestion is managed. The first are known as feeds. This option allows you to set up ingestion feeds that can be pulled using an api, cloud storage bucket or webhook. The second method that is available is the forwarder. The main purpose of the forwarder is to provide the ability to collect data sources that are on prem or are not accessible publicly(for example a VPC without a public IP address). The newest addition to the ingestion methods available is the Bindplane collection agents. These are lightweight OTEL agents that are able to collect data from hosts and either send it directly to Google SecOps or to an aggregating gateway(Examples are bindplane gateway or Forwarder).
Creating An Ingestion Feed
Step 1: Access the Feeds Settings
- Go to the Google Security Operations menu.
- Select "Settings."
- Click on "Feeds." This page shows all existing data feeds.
Step 2: Start Adding a New Feed
- Click the "Add New" button.
- A window titled "Add feed" will appear.
Step 3: Name Your Feed
- Enter a unique name for your new feed in the provided field. This is required for new feeds.
Step 4: Choose Your Data Source
- From the "Source type" list, select the source where your data is coming from (e.g., Amazon S3, Google Cloud Storage).
Step 5: Select the Log Type
- From the "Log type" list, choose the type of logs you want to bring in (e.g., Cloud Audit logs, Firewall logs). The available options depend on the source type you chose.
- Click "Next."
Step 6: Configure Source-Specific Settings
- If you choose "Google Cloud Storage," use the "Get service account" option to get a unique service account for secure access.
- Fill in the required parameters in the "Input Parameters" tab. These vary based on your source and log type. Hover over the question mark icons for guidance.
- (Optional) You can specify a namespace to organize your assets.
- Click "Next."
Step 7: Review and Submit
- Double-check all the settings on the "Finalize" tab.
- Click "Submit" to create the feed.
Step 8: Validation and Data Fetching
- Google Security Operations will validate your feed configuration.
- If it passes, the feed will be named, submitted, and Google Security Operations will start fetching data.
Managing Forwarders
Understanding Forwarders
Forwarders collect security data from your devices and send it to Google Security Operations for analysis. Setting them up involves two main steps:
- Install the forwarder in your environment using the following instructions
- Add Forwarder Configuration: This sets up the basic framework for your forwarder.
- Add Collector Configuration: This tells the forwarder where to get the data from. You need at least one collector for the forwarder to work.
Step 1: Add a New Forwarder
- In Google Security Operations, click "Settings" in the navigation bar.
- Under "Settings," click "Forwarders."
- Click "Add new forwarder."
- Give your forwarder a name in the "Forwarder name" field.
- (Optional) You can customize advanced settings under "Configuration values."
- Click "Submit."
Step 2: Add a Collector to the Forwarder
- After submitting the forwarder, the "Add collector configuration" window will appear.
- Give your collector a name in the "Collector name" field.
- Choose the type of logs this collector will gather from the "Log type" list.
- (Optional) Fine-tune the collector under "Configuration values."
- (Optional) Adjust "Advanced settings" like how often data is sent.
- If you enable "Disk buffer," you can set where temporary data is stored.
- Choose the "Collector type" (the method used to collect data). Each type has its own settings.
- Click "Submit."
Important Notes:
- You can add multiple collectors to a single forwarder to gather different types of data.
- To deploy the forwarder, you'll need to download its configuration and install it on the machine where you want to collect data.
- Refer to the "Install and configure the forwarder" documentation for detailed instructions on installation, configuration settings, and supported data sets.
Configuring Bindplane Agents
The bindplane ingestion pipeline uses Open Telemetry agents to collect an expanding amount of data sources. Google Cloud has been a long term partner with ObserveIQ Bindplane and now brings this useful tool to Google SecOps. For an in-depth understanding of Bindplane and how it works with Google SecOps please see our documentation and a great blog series by GCS engineer Chris Martin. Below is a step-by-step guide to get you started.
- Understand the Need: Chronicle SIEM's Chronicle Forwarder has limitations (Windows Event Logs, databases, text files). BindPlane OP with the OTel agent addresses these.
- Enable the Collection Agent: In Google SecOps, enable the Collection Agent (currently in preview). This adds a "Collection Agents" tab.
- Get a BindPlane License: Request a free BindPlane for Google license if you are a Google SecOps user.
- Deploy BindPlane OP: Deploy BindPlane OP from the GCP Marketplace. This sets up the BindPlane platform(SaaS version available from ObserveIQ Bindplane can also use the Google License)
- Address Shared VPC and Policies (if needed): Configure Shared VPC roles and adjust GCP Organization Policies (trustedImageProjects, requireShieldedVm) if required for Marketplace deployment.
- Access BindPlane OP: SSH into the BindPlane VM to access default credentials and configuration (/etc/bindplane/config.yaml). Change default password.
- Configure BindPlane OP: Configure BindPlane OP's listener (e.g., restrict to IPv4) and create firewall rules to allow traffic on port 3001.
- Start and Access BindPlane OP: Restart the BindPlane service and access the web UI via browser.
- License and Initialize: Enter your BindPlane license key and initialize your BindPlane account upon first login.
- Install BindPlane Agent: Use the BindPlane OP web UI to generate installation instructions for the agent on your target host (Windows or Linux).
- Create a Configuration: In BindPlane OP, create a new configuration for your agent. This defines what logs to collect and where to send them.
- Add Sources (e.g., File): Within the configuration, add log sources (e.g., "File" for text files). Configure file paths and multiline options.
- Add Destination (Google SecOps): Add "Google SecOps" as the destination. Provide JSON service account credentials, set the log type, and map fields.
- Add Processors (for Ingestion Labels): Add "Add Fields" processors to your sources to add chronicle_log_type ingestion labels for proper parsing in Chronicle SIEM. Place Ingestion Labels in "Attribute Fields."
- Configure Windows Event Log Collection: For Windows, use the WINEVTLOG source and configure it appropriately for standard channels or specific channels like Sysmon or Defender.
- Configure Database Collection(Optional Data Source Use Case): Use the sqlquery receiver in a custom source to collect data from databases (MySQL, Postgres, etc.). Be mindful of the tracking_column and storage setting for persistence.
- Configure Multi-line Log Collection: Use the "Multiline Parsing" option in your source configuration with a regex to combine multi-line logs into single events.
- Filter Logs: Use "Filter by Field" or "Filter by Condition" processors to include or exclude logs based on their content. Use "Parse with Regex" to extract fields for filtering.
- Upgrade Agents: Use the BindPlane OP web UI to remotely upgrade agents.
- (Optional) Archiving Pipeline: With a BindPlane license, configure a "GCP Operations Logging" destination to archive logs to Google Cloud Storage.
Practical Application: Security Analytics
The next step to creating a Use Case is planning the detection strategy. The Data Components highlighted in the previous section are mapped to specific ATT&CK Techniques. In addition specific Techniques used by adversaries that might target the organization are given in the threat profile. Notice that in addition to the TTPs provided by ATT&CK Mappings you also want to consider other security reports(including Mandiant Intelligence TTPs) and findings by a threat hunting team. The ATT&CK Techniques that are guiding the detection decisions also have been mapped to several Security Controls Frameworks for reference and documentation purposes.
With this set of information detections can be chosen based on the TTPs that they are intended to cover. This provides a very clear roadmap for detections to be implemented instead of just deciding on random rules that may help. The GCTI Curated Detection Rule Sets are all mapped to ATT&CK Techniques and we highly recommend mapping all custom detections to ATT&CK as well.
Detection Management Overview

The detection management UI is made up of four main views. The first is the Rules Dashboard which will show statistics regarding the custom rules you have added to the platform. The information provided includes recent rule results, severity level assigned and other pieces of data about the rules current configuration. The second is the rules editor where you can write and deploy custom rules to the platform. Please refer to our Yara-L documentation for more information on writing custom rules. The next section is the Curated Detections which are sets of rules provided by our Google Cloud Threat Intelligence team. These rules are available out-of-the-box to provide instant detection coverage for a wide range of threats. The exclusions tab allows you to make custom exclusions that will apply to the curated detections so they can be tuned for your environment.
Using Curated Detections

- Choose the ruleset that wish to enable on your instance
- Decide if you wish to enable the rule as a precise detection or broad detection
- Precise detections are recommended for alerting while broad detections are only recommended for collecting threat hunting and investigation data as they can produce high amounts of false positives.
- Ensure that your Curated Detection capacity will not be exceeded based on the capacity points shown in the rule set information.
- Relevant MITRE ATT&CK tags are available to assist in deciding which rule sets to enable
Example Workflow for Choosing Curated Detections
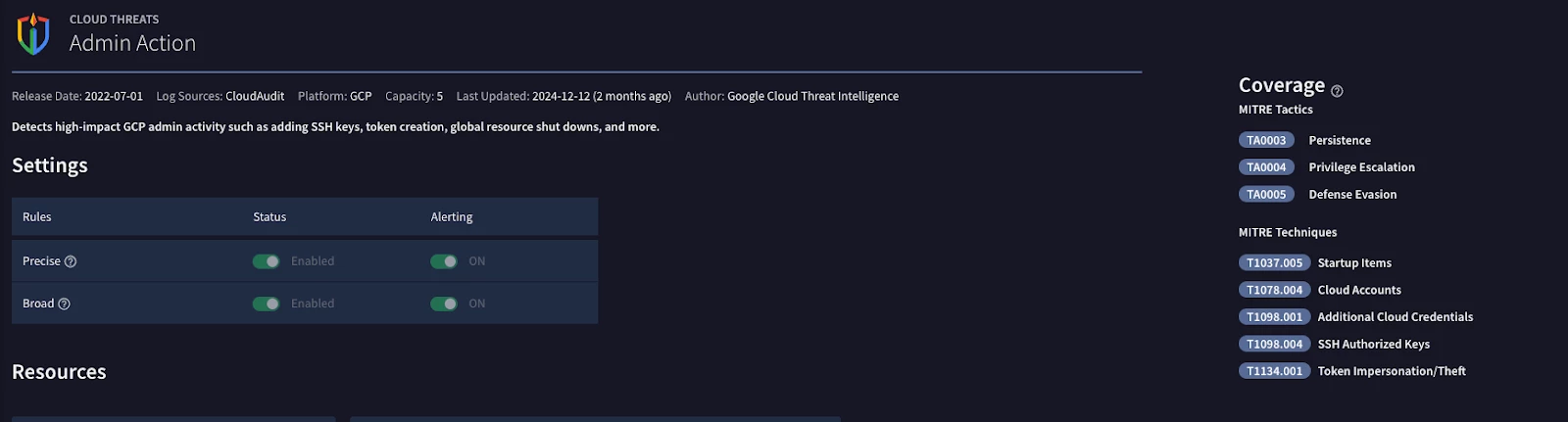
- Based on your threat profile and critical asset analysis it should be possible to highlight Use Cases that should be prioritized.
- Choose the Use Case that the detections will be covering. In the example above GCP threats are the chosen use case.
- Using threat intelligence reports and the previous experience of your organization put together a possible chain of actions an adversary might take when attacking the resources. The Techniques Inference Engine(created by the Center for Threat Informed Defense) can help with associating techniques together.
- In the example above it is assumed that an adversary will attempt to use admin actions to undertake one or more of the ATT&CK Techniques provided on the right of the screen.
- Enable the Curated Detection as described in the previous section
- Ensure that a response playbook has a trigger that will automate the remediation workflow.
Practical Application: Response Orchestration
The next step in Use Case Design is response orchestration. This phase involves the creation of automation playbooks. These playbooks are intended to use the pre-defined critical entities to provide automated searches that analysts would usually have to perform manually. Your organization might follow a standard procedure for investigating events and it is best to plan these further investigation steps so they can be included in the playbook. This not only adds to the benefits of automation but will also help new analysts to quickly investigate a complex case.
The playbooks should be based on templates that cover the main data source categories that have been identified in the previous steps. It is best to organize playbook templates based on the ATT&CK Data Sources they correspond to. This makes it easier to match the proper playbook to the applicable alerts, but also provides a way to categorize the playbooks logically when the repository grows larger. Highlighted here is the need to pre-plan what metrics and CTI are going to be used in reporting as you will be collecting that throughout the playbooks. Designing them with this fact in mind will save hours of editing later.
Playbook Best Practices
Playbooks are a straightforward mechanism that should mimic your SOC processes, while providing an ease and full incident handling ability. It is highly recommended that playbook use case docs be used to prepare the workflow before building the playbook in the editor. This allows for planning by all affected departments, and provides documentation that can be reviewed at a later date. The Use Case doc is usually done in an outline format, but if flow charts are preferred they can also be used.
The main goal is to build what is needed as far as your defined processes go. Some use cases could be fully manual while others might have partial or full automation. Depending on the solutions you are integrating with, playbook development can take into account data that has been processed by previous actions and make decisions by splitting the flow into two or multiple branches and later unite relevant outcomes together into a successful finish line.
Below is a set of Best practices to consider when planning and implementing a Secops playbook.
Triggers
The Triggers for playbooks can be set for specific products, alert names, tags or any custom trigger that might be needed. The main point to remember is that each alert will only trigger one playbook, and so it is important to test your triggers to make sure the proper playbook is being deployed. In addition you can set priorities amongst your playbooks in case there are some that are more fallback workflows versus the main desired result.
Response Handling Stages
Incident Handling Stages are an important part of the SOC organizational planning. Dividing incident handling into different stages allows for more granular scaling, R&R as well as other activities. Stages provide an important method to keep track of metrics. By separating the case workflow in stages that have specific goals it is possible to measure quantifiable mean time stage durations that can help you identify bottlenecks that are inefficient and need to be changed. In the example below the Triage stage is set to be completely automated while the assessment stage takes place once a human analyst is involved. This separation assists in understanding what time inefficiencies are created by the automated action versus the time an analyst is spending during their investigation and decision making process. You can breakdown manual actions being taken during the later stages and eventually automate them possibly in the triage stage. A very good example would be queries that analysts find themselves using often. These could be standardized to automatically run during the triage stage. With proper usage of stages when building response playbooks it becomes easier to locate these possible bonuses to efficiency.
Below is an example of Stages that you can use and when:
Example #1
Triage – automatic stage, where SecOps receives the alert and performs data enrichment
Assessment – automatic or manual, where alerts are getting worked and analyzed and F.P alerts are identified.
Investigation – stage where possible true positives are further analyzed and alert is either closed or escalated for remediation
Remediation: this stage is where actions to contain affected assets and remove possible related threats. Eventually returning all assets to full operation.
Post Incident – stage where ticketing systems get updated, etc.
Example #2
PICER(L) Methodology (SANS Institute)
Preparation – This phase as its name implies deals with the preparing a team to be ready to handle an incident at a moment’s notice
Identification – This phase deals with the detection and determination of whether a deviation from normal operations within an organization is an incident, and its scope if the deviation is indeed an incident. False Positive alerts are typically dropped during this stage.
Containment – The primary purpose of this phase is to limit the damage and prevent any further damage from happening.
Eradication – This phase deals with the actual removal and restoration of affected systems.
Recovery – The purpose of this phase is to bring affected systems back into the production environment carefully, as to ensure that it will not lead to another incident.
Lessons Learned – The most critical phase after all of the others is Lessons Learned. The purpose of this phase is to complete any documentation that was not done during the incident, as well as any additional documentation that may be beneficial in future incidents
Case/Alert Overview Views and Widgets
A second possible method to visualize data for analysts are widgets that can be placed in either the Case and/or Alert Overview. The default overview layouts can be adjusted in the main settings, while each playbook can also have its own modified widget layout. More importantly you can restrict the data a user can view on a widget using role access. Widgets are a good way to create impactful visualizations ranging from graphs, tables to custom javascript/html. Some marketplace integrations come with predefined widgets, and there are several examples that are able to be dropped in and customized.
One special type of widget available is the case insights. They are created by playbook actions and can be used to display the results of actions. Playbook actions that use insights include General insights and Entity Insights. You can use a jina template to render an insight using more complex logic.

Context Values
Sometimes there are values that we need to track within a playbook, case or perhaps even globally on the platform. This is the job of context values. There is a playbook action that allows you to set a key:value pair for any custom information. Some important uses are tracking ticket numbers from ticketing services or passing key data between several blocks. Context values can be thought of as variables in a programming analogy.
Internal Notifications
While this is specific to exact defined SOC processes, it is more of a recommendation to establish proper internal notification structure that would allow for a collaborated teamwork with transparency and visibility
Example:
SOC notification during:
- Each case stage change
- Incident or case outcome (True Positive and False Positive)
- Important findings
False Positive VS True Positive
Definition and differentiation between False Positive and True Positive flow. What exactly happens when each is confirmed.
The difference between False Positives (FP) and True Positives (TP) in security operations, as well as their respective workflows and consequences. A False Positive occurs when a security alert is triggered by a benign event, while a True Positive correctly identifies a malicious event.
- False Positive (FP) Confirmation involves investigation and analysis to determine the benign nature of the event. Root Cause Analysis (RCA) may be conducted to understand the reason for the false alarm, and system adjustments may be made to prevent similar FPs in the future. Consequences of FPs include wasted time and resources, alert fatigue, and reduced confidence in the security system.
- True Positive (TP) Confirmation triggers incident response procedures, including containment, mitigation, forensic investigation, remediation, and recovery. The incident is documented and reported, and lessons learned are used to improve security posture. Consequences of TPs can include data loss, system disruption, reputational damage, and legal or regulatory consequences.
Accurate differentiation between FPs and TPs is crucial for effective incident response and resource allocation in security operations.
Example:
The investigation phase is where T.P and F.P are identified. False Positives are dropped into the branch that finishes required actions and closes the case and True Positive continues and pushes the case stage into Incident.
Different Security Operations Centers may adopt this to their specific needs, depending on processes. Sometimes, SOC does not respond to incidents and the flow is further escalated to an external party or different department, who would then take the action.
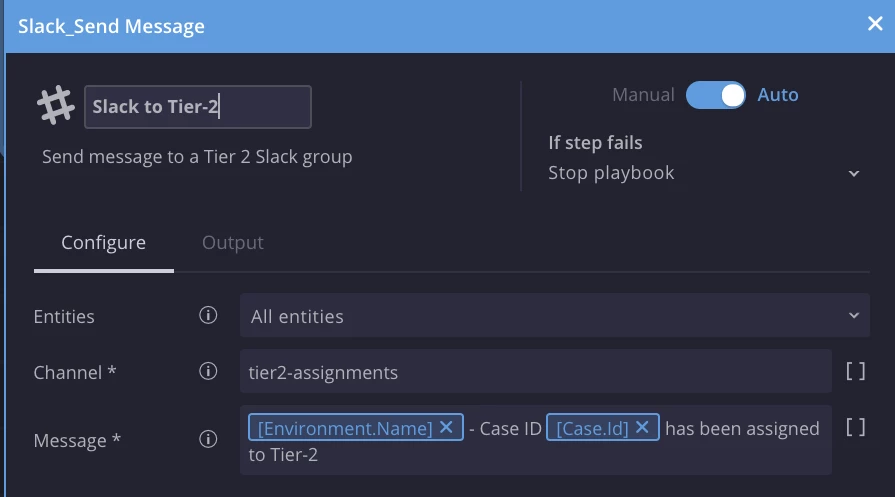
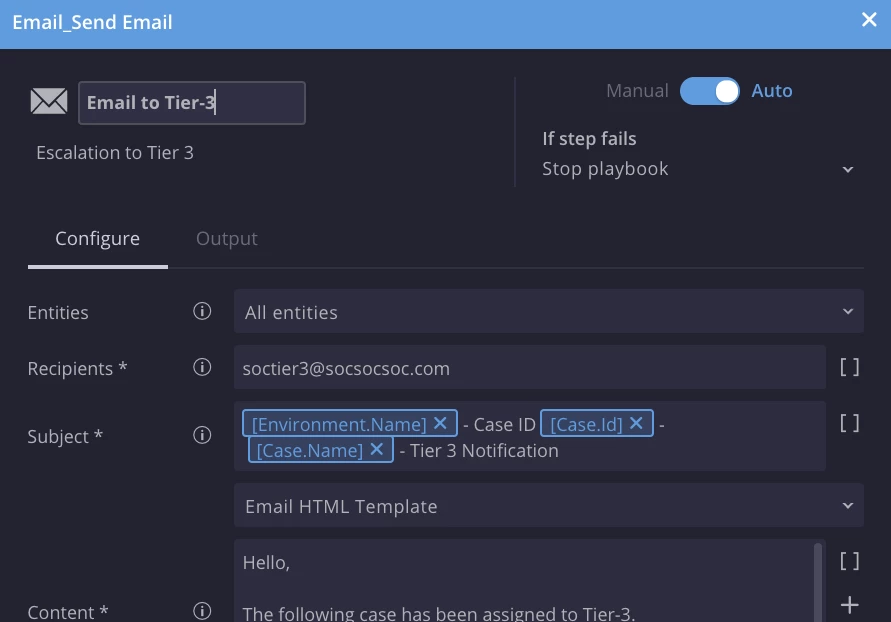
SecOps Case TAGs:
The use of SOAR TAG is recommended for any actions that may be relevant and required under search tab, dashboards and reports at any moment of time.
An example would be for every Notification sent over to the internal FW department or when the case gets assigned from one tier to another – use “FW Team Notified” or “Tier 2 assignment” tags, which will later add value and flexibility to SecOps Dashboards and Reports. How many escalation calls were made? How many times a playbook went into a particular branch, compared to others? Etc.
Anything that is specific to your environment is recommended to be tracked using TAG. Not only, it will allow you to search for those actions when needed, it would also allow for scaling.
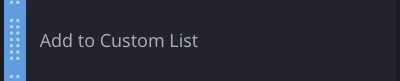
SecOps Custom List
SecOps Custom list is recommended to be used for any activities that require a comparison against a list. In some cases, a different approach is required depending on certain variables.
Create a custom list under SOAR settings and use “add to custom list” and “is in custom list” actions later to compare and add values into the list.
Example:
VIP employees or Critical endpoints might have a slightly different approach when it comes to incident response. Ability to create and check the values inside the custom list would allow you to further divide the flow into few branches with appropriate actions.


Alert Misconfiguration and Lessons Learned
SecOps recommends defining a process that would allow for identification of Misconfigured systems. This can be done as part of the Lessons Learned stage along with additional activities that might be related to documentation enhancement, alert reviews, ticketing system updates, etc.
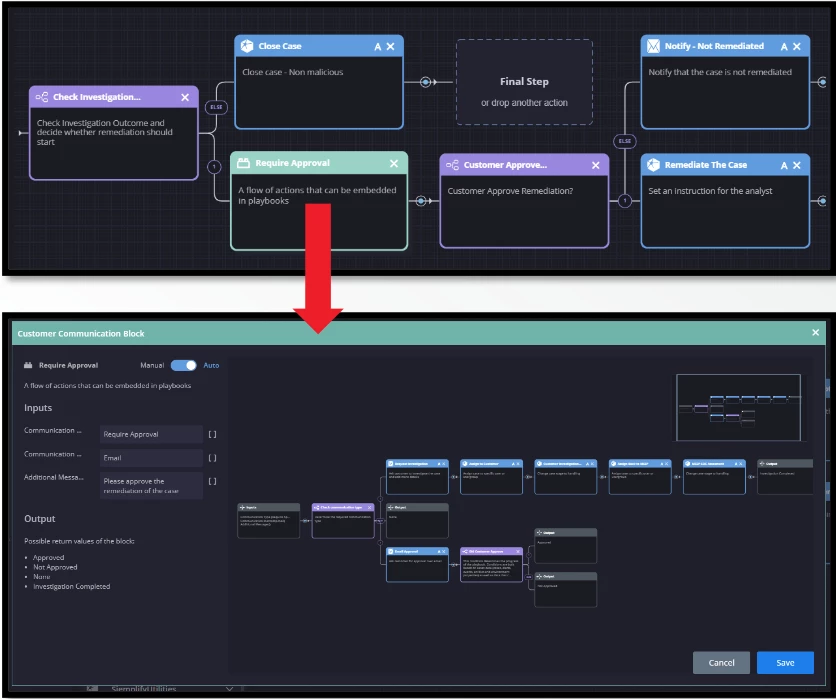
SecOps Playbook Blocks
SecOps recommends using Blocks for any repeatable processes across use cases with similar actions. Utilization of blocks would allow you to pre-configure and attach the same set of action blocks to multiple playbooks and avoid having dependencies across the platform.
Example:
Use blocks during the enrichment phase, where the flow repeats itself. Pre-configure actions that might be beneficial for multiple use cases at the same time. Configure the action blocks to continue if fails to avoid breaks in automation. Use similar enrichment actions at once in order to receive the most data at the end of its cycle.
Practical Application: Continuous Feedback
Continuous Feedback includes the tuning of detection rules, threat intelligence from the local environment, tactical operating improvements and strategic business direction. This feedback will take many forms depending on the type of information and intended audience. It will drive advanced programs such as purple teaming, help prioritize technology acquisition, improve internal procedures and provide executive leadership with a clear picture of the risks they must plan for in the future. All of this feedback must then find its way back into the continuous loop of the workflow and improve the next iteration.
Overview of Dashboards and Reporting
Google SecOps provides the ability to present metrics for both the tactical and strategic levels. The native dashboards, currently referred as Preview, provide the use of Yara-L statistical search as the building foundation. This means that the same language used for rules and search is also directly applicable when drilling down into the data needed. Previously used Embedded Looker dashboards are still supported under the SIEM Dashboards option. The SOAR Dashboards tab leads you to a set of dashboards meant to provide a quick and easy interface to get useful information on your Automation ROI and status. The SOAR Advanced Reporting feature is an embedded Looker Dashboarding tool that allows you to collect Case level data across your organization. The combination of tactical information on alert trends, high risk entities and data ingestion stats provide a wide range of visibility for your team. On the strategic level the Case level information available in the SOAR dataset provides strategic information like performance metrics, automation pipeline statistics and other key areas that can help your leadership make informed decisions.
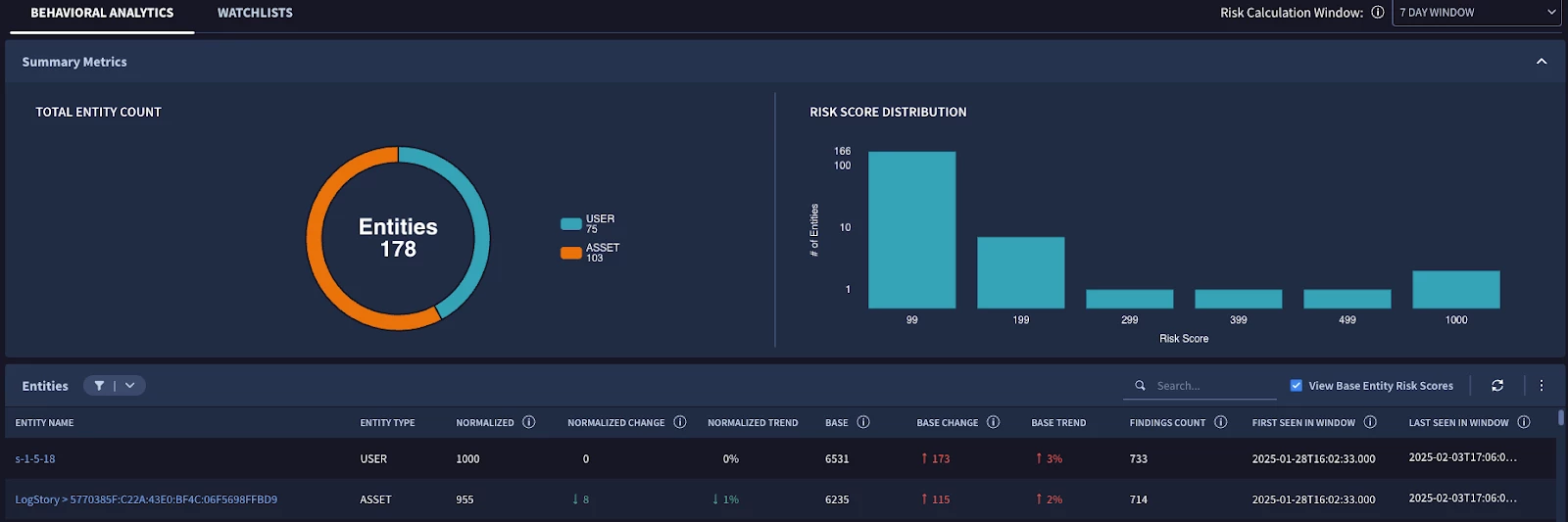
Google Secops also provides a Risk Analytics dashboard that helps your organization build ongoing behavioral intelligence on assets and users. The risk analytics dashboard is driven by both Curated UEBA detection sets and any custom logic added to your own detections. Watchlists are also available for the most important assets that may carry a higher risk value. For a more depth guide on using the Risk Analytics features please see our documentation.
Conclusion:
In adopting a robust data ingestion and standardization approach, organizations can ensure consistency, accuracy, and scalability in their security operations. By applying the principles of Continuous Detection & Continuous Response (CD/CR), teams can enhance threat detection and response efficiently. Practical implementation, supported by well-structured playbooks and industry best practices, enables a streamlined, proactive security posture. By following these guidelines, organizations can build a resilient and adaptive security framework that evolves with emerging threats and operational needs!
Thank you for taking the time to read this guide - we appreciate your commitment to building a stronger security foundation!