


This is Part 2 of a four-part series on running many tenants on one Google SecOps instance. Part 1 set up the mental model: multi-tenancy is three independent isolation problems (ingestion tagging, data access, case routing), and one hierarchical slug per tenant, used byte-for-byte across the namespace, the Data RBAC scope, the SOAR environment, and the Bindplane project (when applicable), is the thread that ties them together. This part takes up the first plane: ingestion.
In Part 1 the namespace did all the work. We said: stamp each tenant's telemetry with its slug at ingestion, and the SIEM and SOAR layers have something to key off. That sentence hides the entire problem of this article...
The moment you ingest telemetry from an organization you do not fully control, two questions open up that have nothing to do with access control and everything to do with whether you can trust what just arrived:
- Can someone get access to the credential that lets you write into your SIEM?
- Can one third party's data end up wearing another's tag, by accident or on purpose?
Getting many tenants onto one instance is, first and foremost, getting their telemetry in correctly labeled, without trusting their machines and without leaking the key that lets anyone write into your SIEM.
This is where multi-tenant SecOps actually gets hard, and where a single line in a collector's configuration decides whether your tenants' logs cross the wire in the clear.
Ingestion fundamentals
Before going deeper into the security best practices for ingesting into Google SecOps in a multi-tenant setting, it is worth surfacing a few ingestion basics.
Google SecOps supports several ingestion methods, including:
- Feeds, for SaaS and multi-cloud ingestion of security telemetry.
- Direct-Ingestion, for simple Google Cloud Platform and Google Workspace telemetry shipped straight to Google SecOps.
- Bindplane Ingestion, for on-premise environments and runtime telemetry from the operating system.
- Ingestion API, for shipping raw or UDM-normalized telemetry programmatically through an SDK.
This article focuses on Bindplane Ingestion.
Important: Feeds inherit a reduced set of the risks that on-premise ingestion with the Bindplane agent carries, mostly around keeping the feeds well-configured and organized. It is also worth noting that other methods, such as Direct-Ingestion for Google Cloud Platform and Google Workspace, are not recommended for ingesting a third party's telemetry, because they are settings tied to your own Google SecOps instance. To ingest from a third party's Google Cloud or Workspace environment, look at Feeds or the Bindplane agent instead, or ask your Google SecOps representative about multi-tenancy best practices for those sources.
With the Bindplane agent the procedure usually looks like this:
- Run the Bindplane installation script on the workload.
- Configure the agent to ship its telemetry to the Google SecOps instance.
- Validate that the telemetry is arriving in Google SecOps.
Step 2 alone involves three things: configuring a source (for example, collecting Windows Event logs on a Windows host), configuring the relevant processors (for example, the Google SecOps Standardization processor with log_type set to WINEVTLOG), and configuring a destination (for example, a Google SecOps destination holding the JSON authentication key).
For an internal or single-tenant setting this is often enough to get telemetry flowing quickly. It is not enough, however, once you are serving multiple namespaced tenants.
Two concerns that fail independently
Back in the multi-tenant case, keep these two apart, because they have different fixes and they fail for different reasons:
- Credential isolation: When you create a Google SecOps destination in Bindplane, you have to give it an authentication method so Google SecOps will accept the telemetry. It is common to set the authentication key (the
auth.json) directly in the destination configuration, or as a path to a file on the local device. Either way the concern is the same: can the SIEM ingestion credential be stolen or leaked? A service-account key sitting in a file on a box you do not control is a different risk from a key that never leaves your own infrastructure. - Tenant isolation: When you build a Bindplane configuration you can have a processor label all the telemetry passing through it with a namespace (or with custom ingestion labels). You could build one configuration per tenant, but that quickly becomes a massive maintenance and control burden. And the concern is the same: can one third party's telemetry be tagged, accidentally or deliberately, as another's? A namespace is only as trustworthy as the party who got to set it.
A third question cuts across both and decides how much you can trust what arrives, and it depends on your managed-service model: who owns the control plane?
The control plane is the agent-management layer, the Bindplane UI and CLI that author and push the collector's configuration. Owning the control plane is not the same as owning the device. The operator (for example, the managed-service provider) can fully control an agent's configuration — what it collects, how it processes, where it sends — while the third party still owns the physical machine and its network.
Two words recur, so let me pin them down. The edge is a collector running on the third party's infrastructure, close to their logs; the term covers any collector that does not sit inside your trust zone. The gateway is a collector you, the operator, hold, that proxies telemetry on its way to the SIEM. The whole design space comes down to whether there is a gateway at all and, if there is, what it enforces.
Bindplane Direct Ingestion
Note: Do not confuse Bindplane Direct Ingestion with the Direct-Ingestion method. The former is my shorthand for shipping telemetry to Google SecOps with Bindplane and no intermediary. The latter is a separate ingestion method that is not relevant here.
This is the simplest Bindplane model: a collector runs on an edge host and ships telemetry straight to the Google SecOps ingestion API, with no intermediary. Typically you, the operator, author the configuration (you own the control plane), and the third party's only job is to host the agent.
There is one architecture here with two authentication variants, and the difference between them is the whole credential-isolation story.
- Key-based: The agent holds a service-account JSON key. It is the simplest thing to stand up, and that is its only virtue. The key is a long-lived, sensitive secret sitting in a file on a device you do not control. If that box is compromised, the key is compromised, and anyone who has it can impersonate your ingestion and write into your SIEM.
Note: In Bindplane, you set this configuration in the Google SecOps destination, by selecting theAuthentication Methodoption set tojsonorfile. If set tojson, a fieldCredentialsappears expecting the contents of theauth.jsonfile. if set tofile, a fieldCredentials Fileappears expecting the path to theauth.jsonfile.
Theauth.jsonfile can be obtained in Google SecOps SIEM Settings > Collection Agents.
- Key-less: The agent authenticates with Workload Identity Federation (WIF) through Application Default Credentials, so there is no downloadable key on the box, only a credential configuration that points at an external identity and a service account to impersonate. This removes the leak risk, but the setup cost is real: WIF needs a federatable identity on the edge plus the ADC wiring, and a third party may be unwilling to take that on, although automating the setup is the lever that could turn WIF from an exception into your default. What WIF does not do is block abuse outright. A compromised box can still misuse the ingestion path it legitimately holds, so WIF lowers the impact and likelihood of a leak without erasing the host-trust risk.
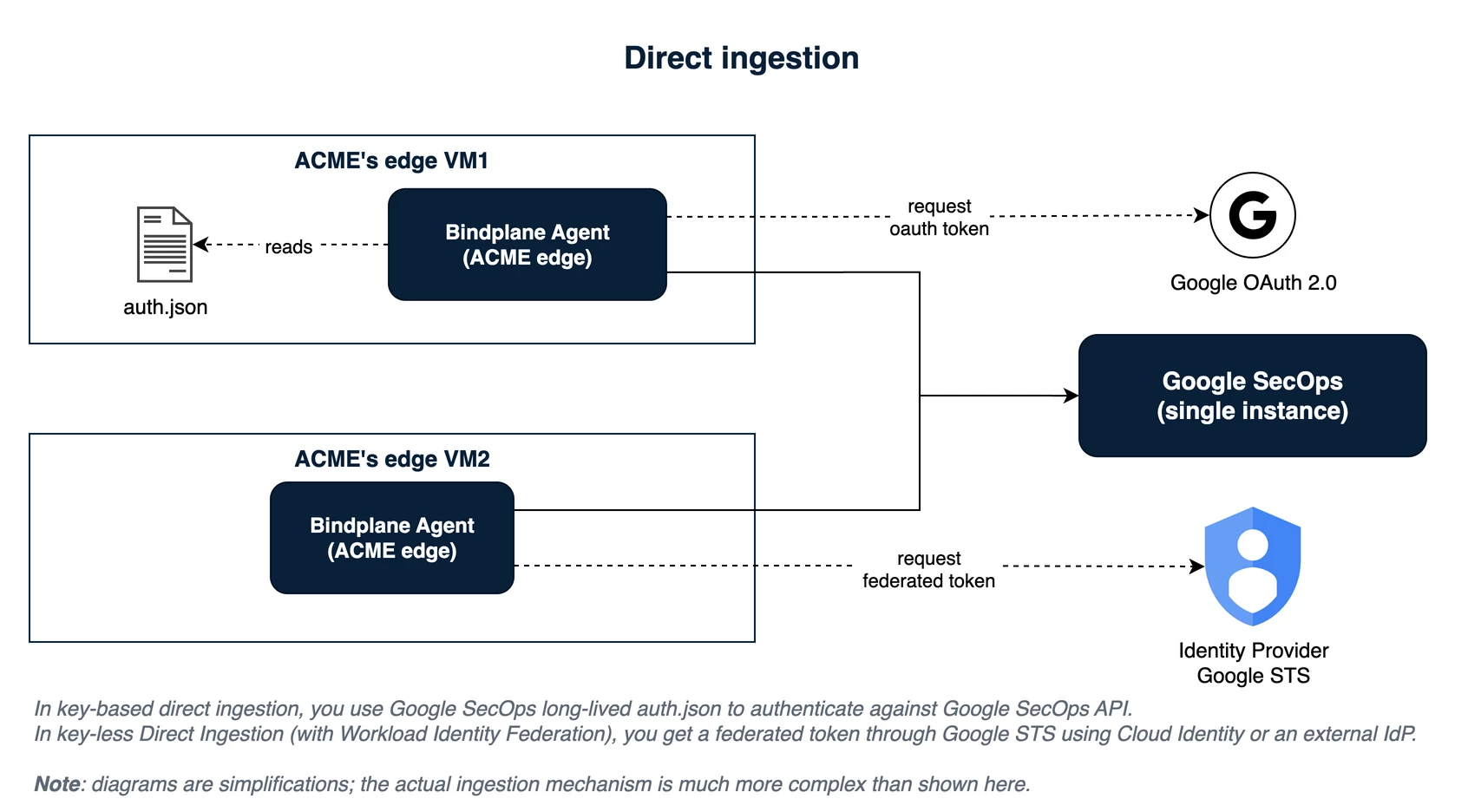
The appeal of direct ingestion is genuine. It is the simplest topology: one configuration per agent, no gateway, no hop to encrypt, no third-party-identity problem, and because you authored the config, the namespace it stamps is inherently yours and therefore trusted. The costs are equally real. You manage N agents across M organizations with no consolidation, the third party has to accept an operator-controlled (often privileged) agent inside their network, and there is one residual that no authentication scheme removes: a third party with root on their own device controls the runtime, so they can still abuse whatever credential the box legitimately holds and assert any namespace they like.
That residual is the whole reason direct ingestion belongs inside a trusted zone — your own infrastructure, or a third party you are willing to treat as fully trusted. You can stretch it to a semi-trusted third party by deciding the simplicity is worth the host-trust residual, but you are no longer pretending the host cannot misbehave. Once the host is genuinely untrusted, direct ingestion is the wrong tool and a gateway is the answer.
Preferred only inside a trusted zone. Direct ingestion, key-based or keyless, is the right tool when the telemetry originates in a zone you trust. WIF is the keyless form that removes the leak risk and SHOULD be your default there; key-based direct is the fallback when WIF's setup is too heavy, at the cost of a long-lived secret on the host. You definitely MUST use keyless direct for your own trusted workloads, but I do not recommend it for any untrusted layer. For a third party, do not stretch direct ingestion. Instead, go to a gateway, covered next.
Gateway-gated ingestion
Now insert a collector you control between the third-party edges and the Google SecOps SIEM. The edges forward to that mid collector, the gateway, which talks to the SIEM and holds the ingestion credential. The configuration splits cleanly in two: an edge config with the telemetry sources plus a "send to the gateway" destination and no credential, and a gateway config with a "receive from the edges" source plus the SIEM destination that holds the credential (or not, with WIF authentication) and stamps the namespace. One gateway config can serve many edges.
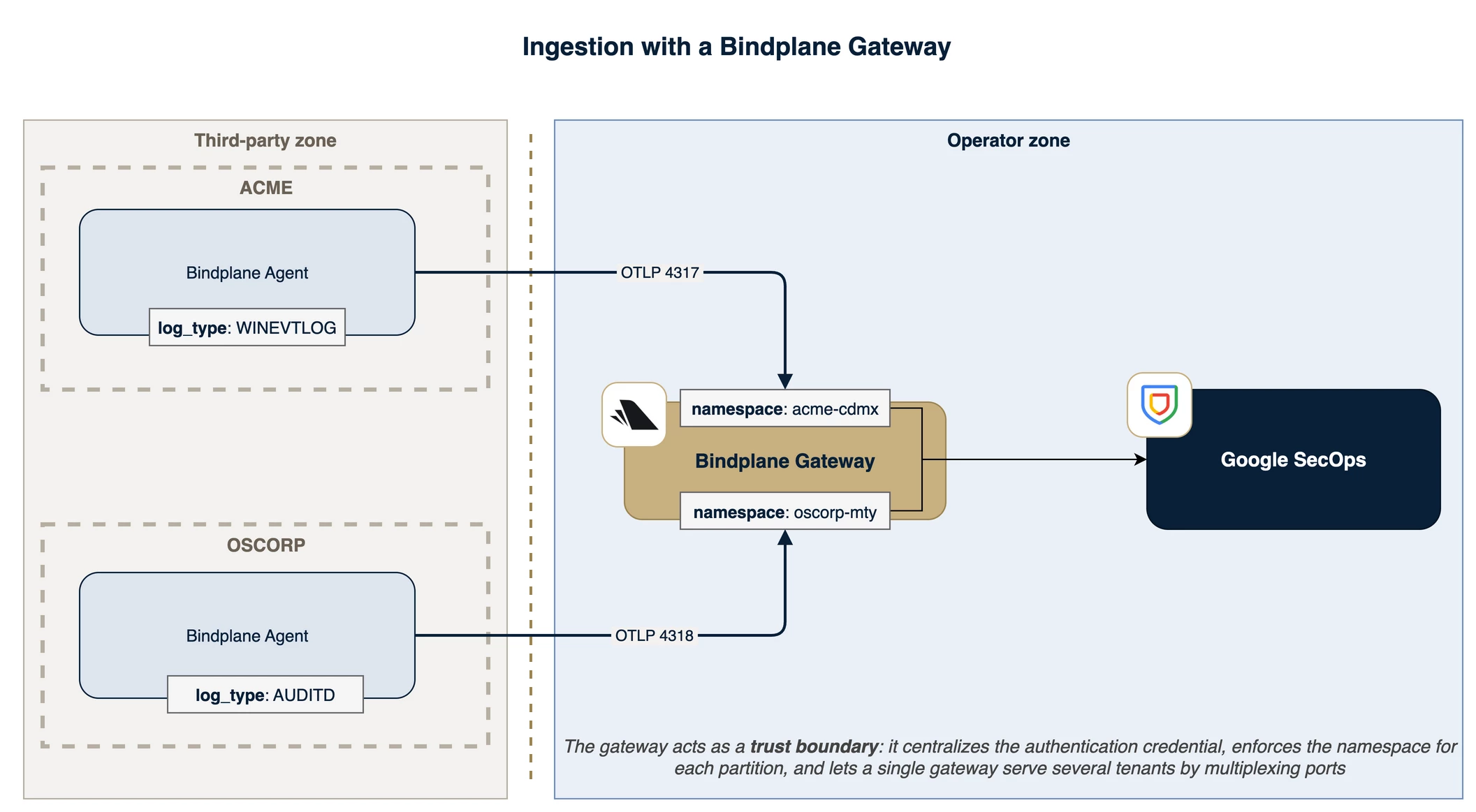
What this buys you is the credential-isolation win. The SIEM credential leaves the third party's box entirely and lives only in your trusted zone, where they can neither extract it nor infer it. And because the gateway is the last hop before the SIEM, it is also where you get to re-assert the namespace rather than trust whatever arrived. A gateway is not free, though, and it introduces three standing concerns that every gateway design has to answer.
First, the edge-to-gateway hop crosses the internet, so it MUST be encrypted. Without encryption, anyone who can capture that hop reads the telemetry itself. (Not the credential, to be clear; the credential never travels this hop. But the logs do, and that is bad enough, as the next section explains.)
Second, a shared gateway is a single point of failure. At real ingest volumes the collector's local disk buffer is a rounding error, and an outage does not merely risk data loss — it blinds the SOC to live telemetry. Therefore, the moment a second tenant depends on one gateway, high availability is no longer optional: you have to deploy several identical gateway replicas behind a load balancer.
Note: Setting up Bindplane HA is not covered in this article. I'll recommend surfacing Bindplane docs.
Third, if third parties share a gateway, you MUST be able to tell whose telemetry is whose. This is the identification problem.
Telling tenants apart on a shared gateway
The one gateway collector (or gateway collector cluster in HA) runs several Bindplane Gateway sources, each bound to its own port. A "listener" is just a source (the Bindplane Gateway) on a port. Having the core elements defined, you tell ACME to send their telemetry to port 4317 and OSCORP to port 4318, and each per-port pipeline carries its own processor that stamps that tenant's namespace.
The port is the routing key, so nothing exotic is needed. The catch is the line between identification and authentication: a port tells you which namespace to stamp, but a labeled door is not a locked door. Anyone who can reach ACME's port can pose as ACME, so each port still needs an authenticator, which could be a firewall allowing only the third party's source IP (if it is static), a tunnel between their network and the chosen listener, or mTLS (the best option by far).

Note: This model also suits cases where a third party needs to isolate its own telemetry internally. If ACME has two data centers, one in Mexico City and one in Guadalajara, you can give one listener toacme-cdmxand another toacme-gdl.
Tip: keep a record of which organizations map to which ports and tenant slugs, and make sure to break down all your available ports into groups. You can assign a small or bigger range of ports depending on the size of the third-party.
Control-plane ownership
Cutting across the topology is a question of responsibility, and it changes where you CAN and where you MUST stamp the namespace.
When the setup is fully-managed and you authored the edge config while the third party only hosts the agent, the inbound labels are generally trustworthy, so the namespace CAN ride a trusted attribute set at the edge, or simply use the Google SecOps destination's namespace fallback. No override is needed, because no third party could have pre-stamped anything. Even so, I avoid leaning on this, for the simple reason it is not compliant with a least-privilege defense-in-depth mindset.
When the setup is partially-managed and the third party authors its own edge collector configuration under its own control plane (e.g. a Bindplane project in the operator's Bindplane account, or one in the third party's own account), the inbound labels are untrusted. You cannot rely on the destination's namespace fallback, because a third party could pre-stamp any namespace it wanted, including someone else's. The operator has to force-overwrite the namespace at a gateway-side processor it controls, and that processor MUST use set-or-overwrite semantics, not insert-if-absent, or a third-party-supplied value survives and your tenant isolation is quietly broken.
Note: This is the preferred configuration even when you fully manage the control plane. It aligns with a defense-in-depth mindset and reduces the risk of potential service abuse.
This is also where the fourth surface from Part 1 — the Bindplane project named after the slug — earns its "when applicable" caveat. Naming the project after the tenant slug is a convenience that helps you organize collectors and their configurations, specially when you own the control plane. It is not strictly necessary when the control plane is partially-managed and the third party runs its own Bindplane account or organization since you do not control their project layout. In every other setting, naming the Bindplane project after the slug CAN help keep the control plane legible.
A shared gateway also receives many log types from one tenant on a single listener (e.g. the Bindplane Gateway source for acme-cdmx on port 4317 might carry WINEVTLOG and AUDITD at once). The implication is that you cannot pin a single log_type at the gateway without brittle conditionals that add ingestion latency, consume host resources, and quickly become unmanageable.
Important: The architecture expects telemetry to arrive already tagged with its log_type by the edge collector, whether or not the model is shared-responsibility. The namespace, however, MUST be set inside the trust zone, on the operator's gateway.
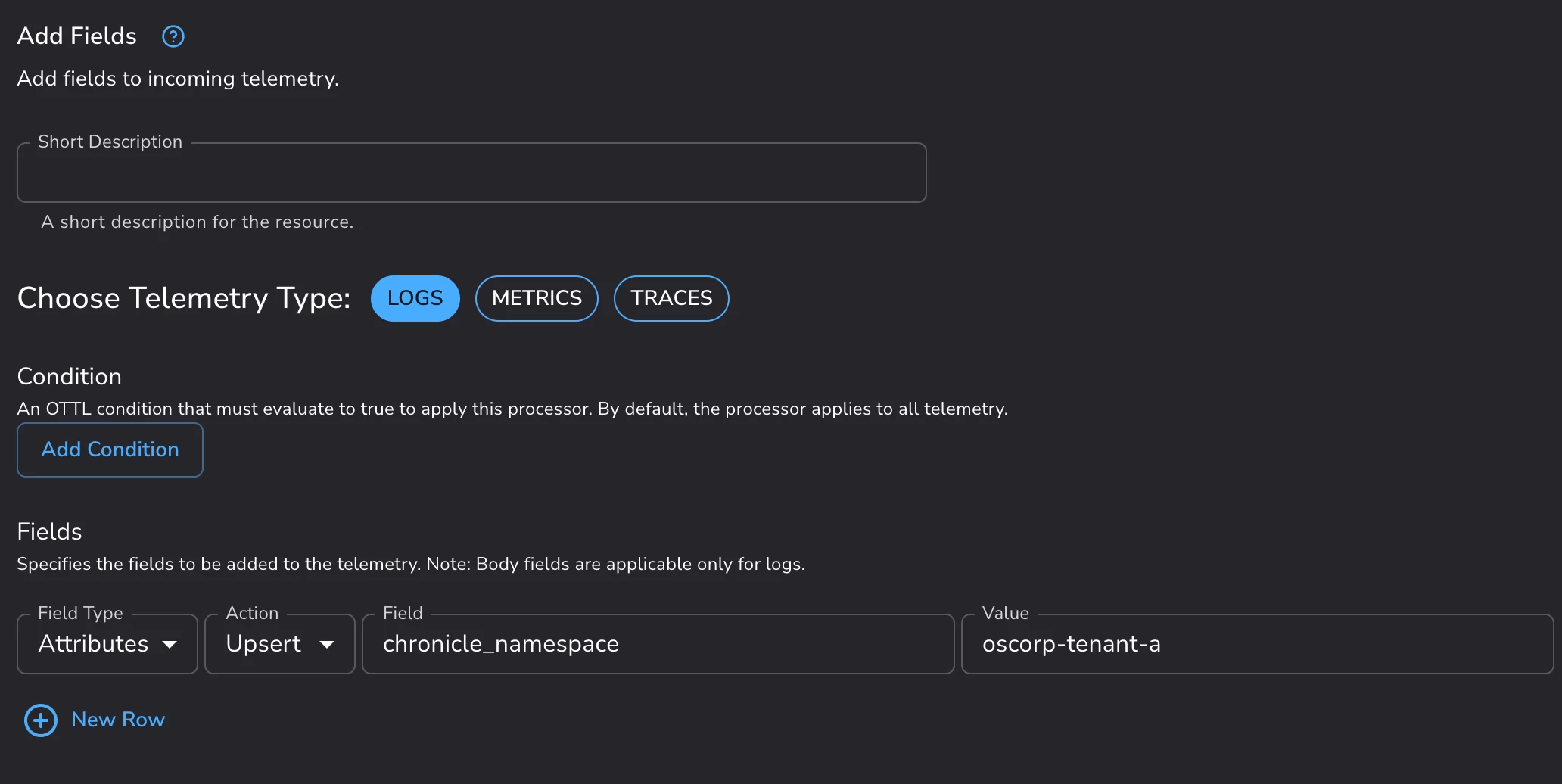
That force-overwrite is worth one concrete note, because the obvious tool is the wrong one. The Google SecOps Standardization processor refuses to stamp a namespace without also setting a log_type. Instead, use the Add Fields processor with the Upsert action on the chronicle_namespace attribute. It force-overwrites the namespace and leaves the log type untouched, which is exactly what you want when one gateway carries telemetry of every shape.
TLS and mTLS
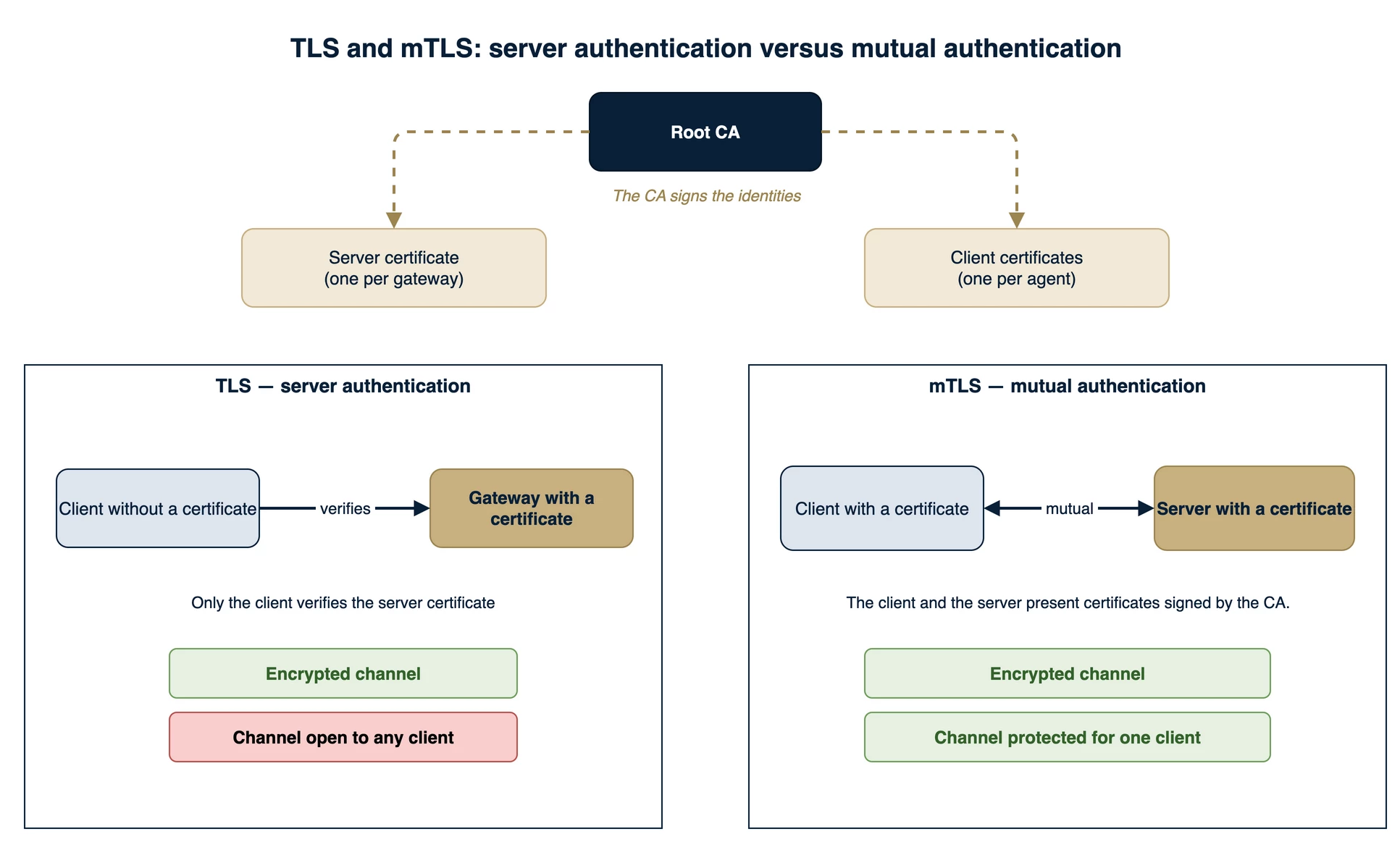
Encryption and authentication are different controls, and a gateway design needs both.
TLS is the non-negotiable floor on any internet hop. It encrypts the traffic and authenticates the server, so the edge knows it is really talking to your gateway. A VPN or tunnel between the third-party edge and your gateway network is an alternative that carries its own encryption and can stand in for TLS entirely, but may be difficult to implement, and third parties may refuse outright. What does not count as a control is hiding the listening port or accepting only the expected protocol; that is surface reduction, useful as defense in depth but never a control on its own.
Authentication of the sender is a separate axis, weakest to strongest: a firewall allowlisting the third party's source IPs (viable only when those IPs are static, and remember you can usually firewall only your own gateway, never the third party's edge); a token or UUID carried in the payload (a bearer secret with leak and replay risk, acceptable only behind TLS, and it needs conditionals); and mTLS, where a client certificate authenticates the sender independent of IP and doubles as a stable identity.
Identification answers "which tenant is this", authentication answers "prove it", and a port or a token can identify without authenticating, which is why a lock is still required alongside.
You do not need to capture a single packet to know whether a hop is encrypted, because the collector's own configuration already answers the question. In the Bindplane Gateway destination that the edge ships to, TLS is governed by an insecure flag. When that destination carries tls.insecure: true (or no TLS block at all), the agent connects over plain HTTP/2 with no handshake, and every log on that hop crosses the wire in cleartext. Reading the configuration and confirming that one line is a definitive answer, not a hint: it is the assertion itself. A packet capture would only re-confirm what the configuration already states outright.
One subtlety trips people up here. Bindplane gzip-compresses telemetry by default, so a capture of an unencrypted hop looks like binary noise rather than plain text, and it is tempting to read that as protection. Compression is not encryption. gzip is trivially reversible by anyone on the path, so compressed traffic is not protected traffic. The only control that protects the hop is TLS, and the one place that tells you whether TLS is on is the destination configuration.
So the check is simple and needs no tooling: open the edge collector's gateway destination and read its TLS setting. tls.insecure: true means the hop is exposed, and you fix it before trusting that gateway; tls.insecure: false means the hop is encrypted.
mTLS closes the gap from both sides. Setting tls.insecure: false encrypts the hop, so even a full on-path capture yields nothing readable, and adding a client certificate means the gateway also authenticates which edge is allowed to connect at all. Same ingestion, same credential isolation, the hop now encrypted and the sender now proven. The biggest residual risk is that a broken certificate breaks the connection to the ingestion pipeline, but it cannot be silently tampered with.
A recommendation ladder
In our experience the choice is rarely your own preference as the operator; it is set by what each third party will accept and who controls the control plane. Here is the ladder I reach for, simplest to strongest.
- Bindplane Direct Ingestion with WIF, in an operator-owned control plane. The right tool when the telemetry comes from a trusted zone — your own infrastructure, or a fully trusted third party that will host your agent. No gateway, no hop, no identity problem; WIF removes the key leak and the only residual is host trust. You CAN stretch it to a semi-trusted third party, but I do not recommend it there, and once the zone is untrusted you SHOULD move down the ladder.
- Gateway-gated, port-per-partner listeners, with a token-like field for simple authentication or mTLS for the robust version. This is the multi-tenant design I recommend by default. TLS encrypts the hop, the port handles routing and the namespace stamp, and the authenticator (firewall, token, or mTLS) is the lock. However, you MUST stand up high availability the moment a second tenant depends on the gateway.
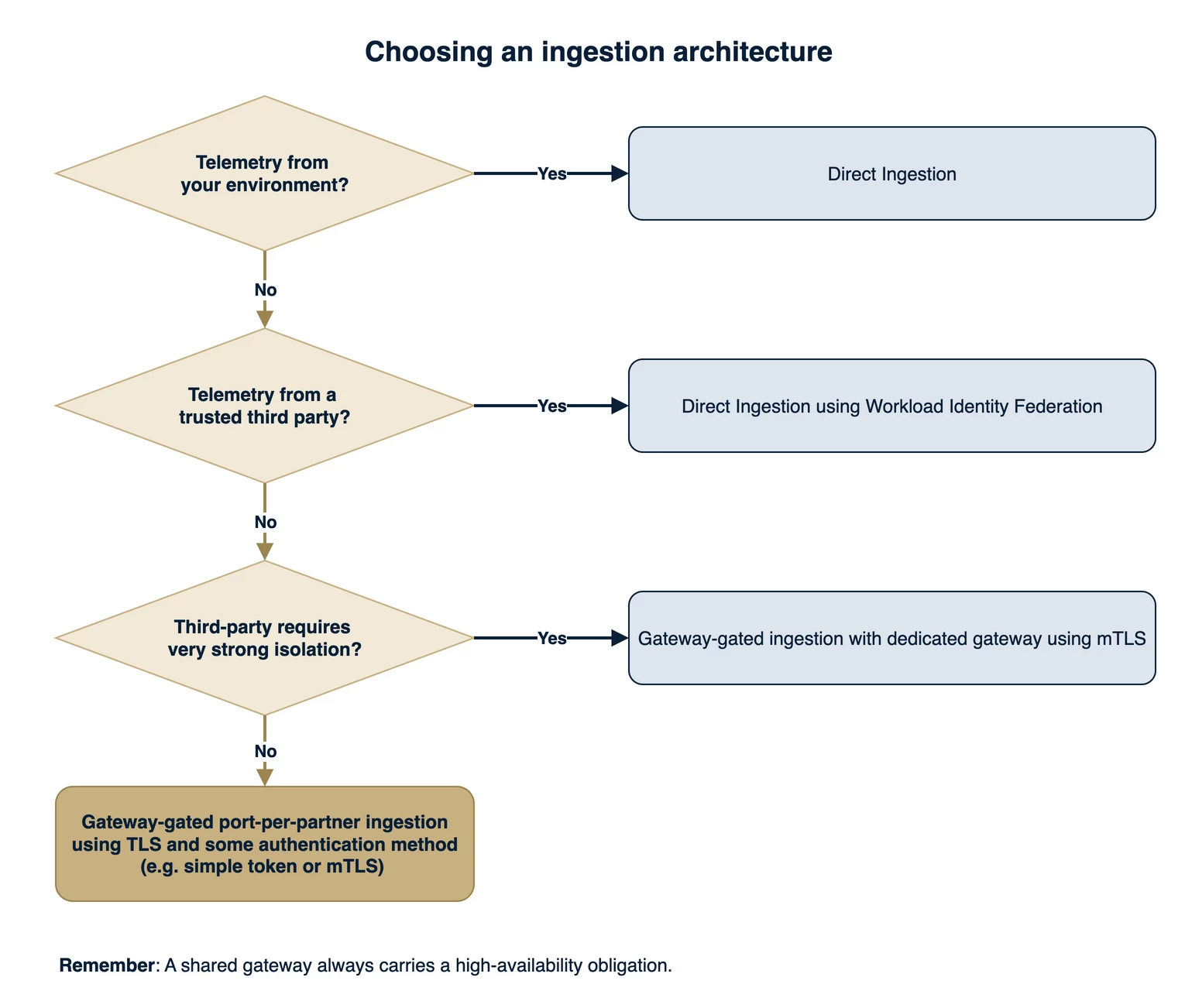
Note: The "reserved listener" branch in the graph is the same port-per-partner gateway, applied to one organization. Nothing new to build, just the stronger option already on the table in Telling tenants apart on a shared gateway, reached for on a per-tenant basis.
Two reminders hold across the whole ladder. Keep credential isolation (WIF and trusted gateways) and tenant isolation (namespace integrity) as separate challenges, because conflating them is how a setup looks safe while one of them is broken. And remember that a shared gateway always carries an HA obligation, from the day a second tenant's visibility depends on it.
Building the recommended default: a port-per-partner gateway
This section is a simple, real-world walkthrough of a safe port-per-partner gateway architecture, the design most multi-tenant operators settle on. Here is the shape of the build, end to end.
In this example, multitenancy is scoped within a single organization, across its several organizational units and their users. It splits into an edge configuration you ship to each tenant and one gateway configuration to support all of them.
The setup below reflects Zevorus's own fully-managed control plane (we, the operator, configure the Bindplane collectors on the edge devices as well), using the slug convention <org>-<unit>-<user> (here, zevorus-ninja or zevorus-ninja-acanton).
Note: This is a fictional use case; you won’t normally give a tenant to a single user.
Important: While you can do this process manually, it is highly recommended to automate this process if it ever becomes a recurrent activity. The more tenants you have to manage, the more likely you are to make a mistake.
-
On each edge, configure the sources and a single gateway destination. Add the telemetry sources the third party needs (Windows Event logs, auditd, and so on) and one Bindplane Gateway destination pointing at the gateway's address and the port you assigned this tenant. The edge holds no SecOps credential and stamps no namespace; its only job is to stamp the log type and forward to the gateway. You MUST turn TLS on for this destination (
tls.insecure: false) so the hop is encrypted from the start, and consider mTLS for more robust authentication controls.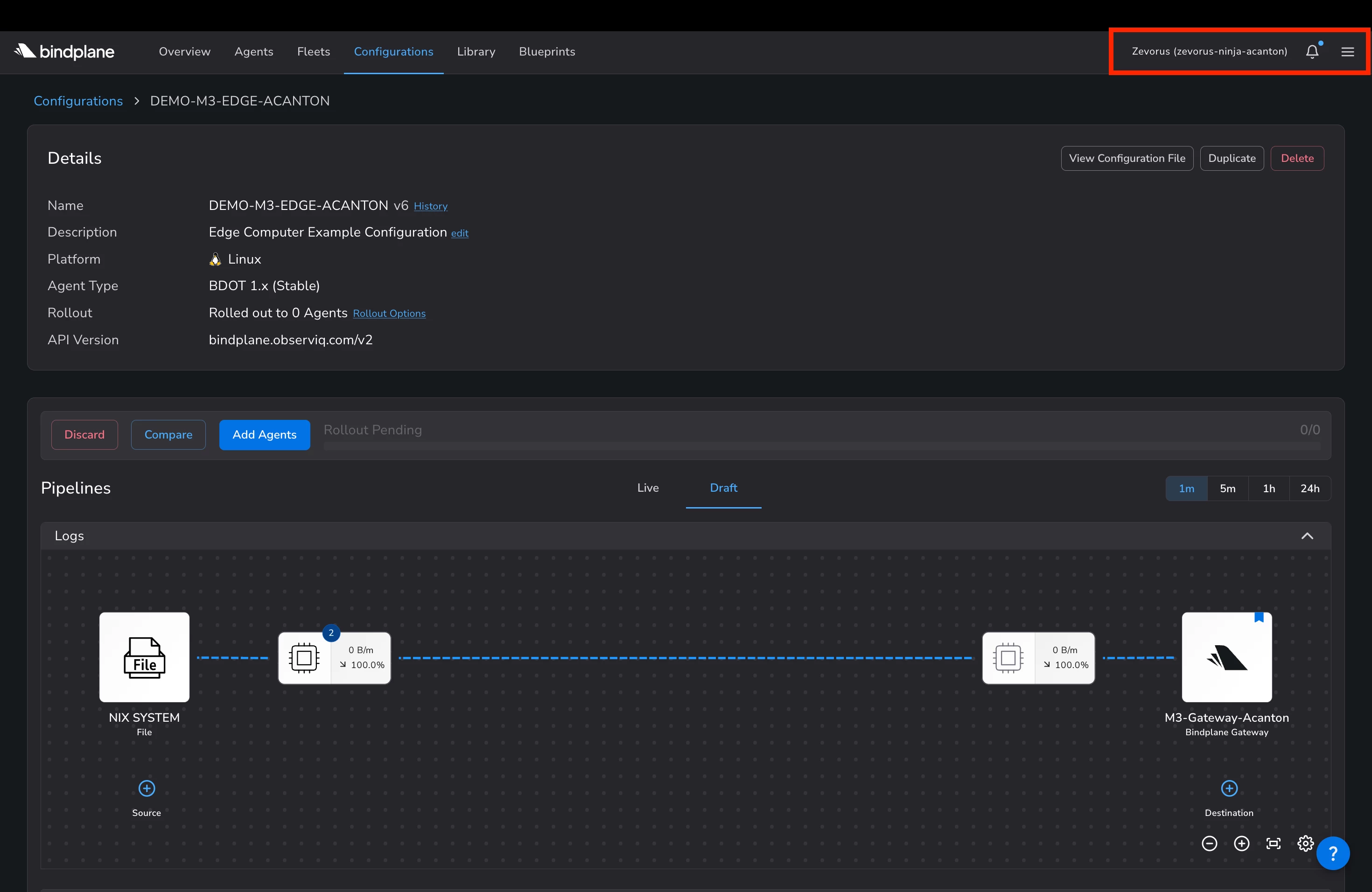
Figure 7 — A real edge configuration, in the zevorus-ninja-acanton project, collecting Linux telemetry (NIX SYSTEM) and forwarding it to the M3-Gateway-Acanton Bindplane Gateway destination. Nothing else lives on the edge: no credential, no namespace stamp. 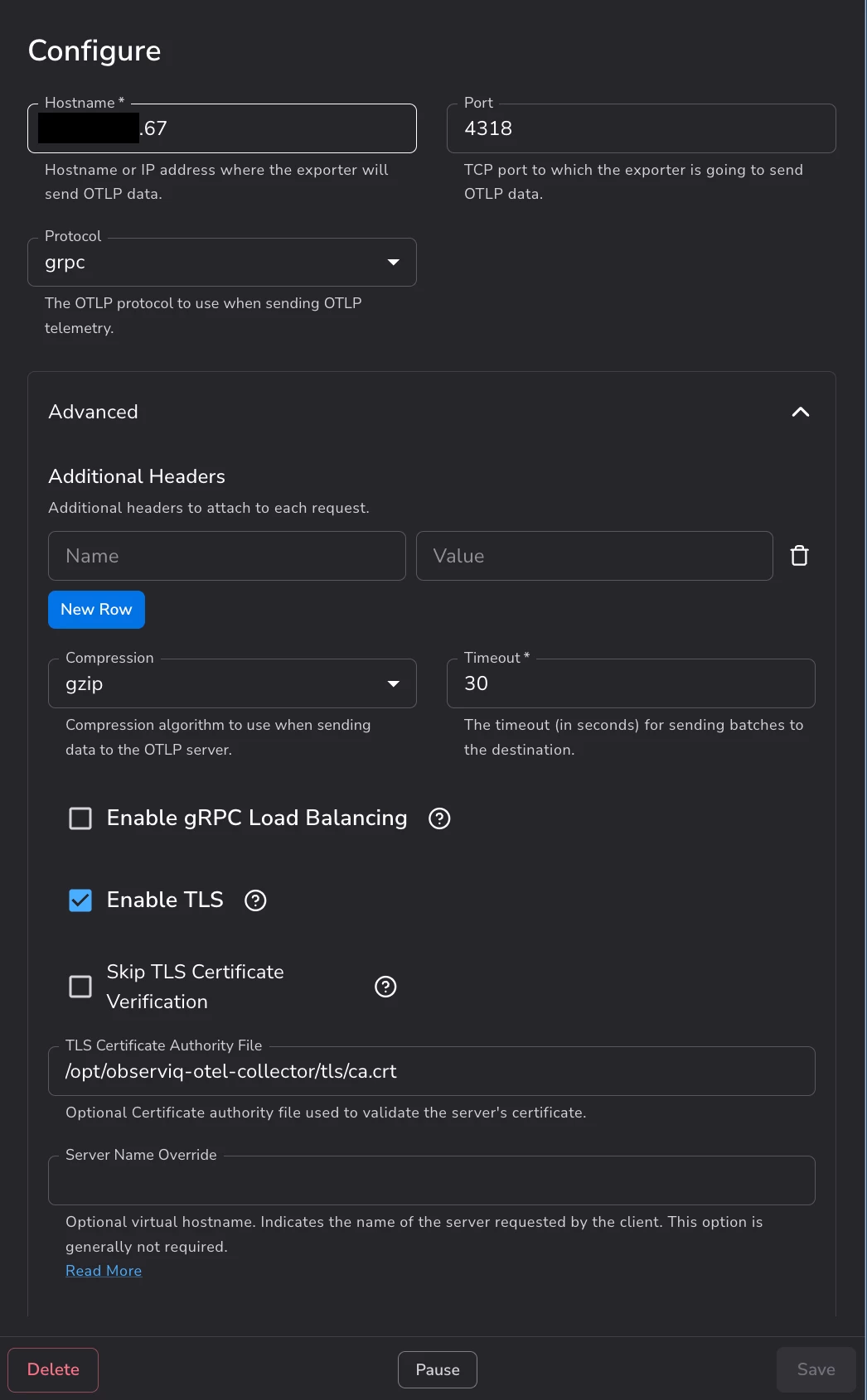
Figure 8 — The edge's Bindplane Gateway destination: gRPC to the gateway's address on port 4318, with Enable TLS checked and certificate verification left on, so the hop is encrypted and the edge validates the gateway's certificate. -
On the gateway, run one listener per tenant. Add one Bindplane Gateway source per assigned port, each on its own pipeline. The port is the routing key: traffic on 4317 is one of Zevorus's units, while traffic on 4318 is one of Zevorus Ninjas users.
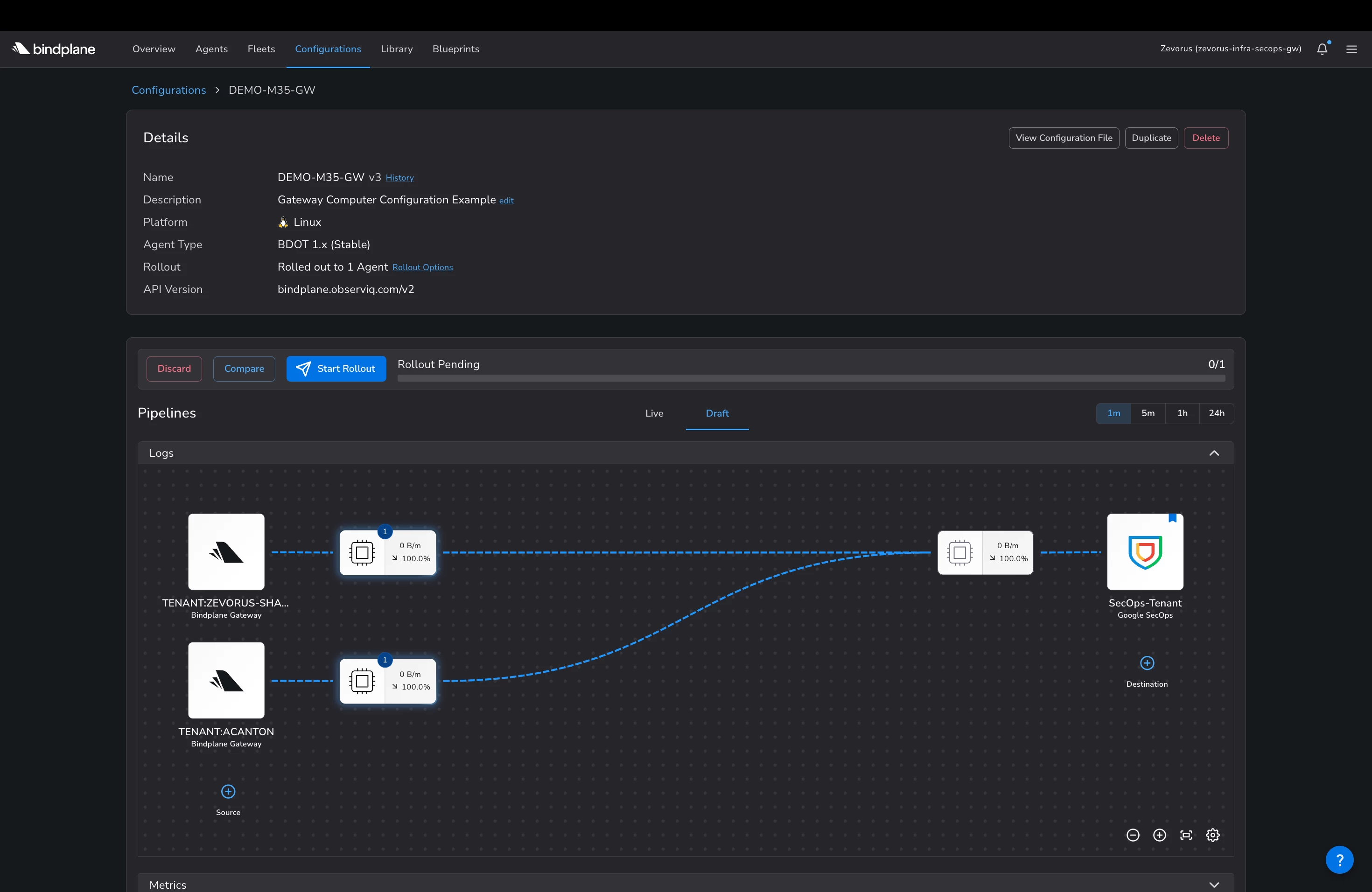
Figure 9 — The gateway side, in the zevorus-infra-secops-gw project: two Bindplane Gateway listeners, one per tenant (TENANT:ZEVORUS-SHA… and TENANT:ACANTON), both feeding the single SecOps-Tenant Google SecOps destination that holds the ingestion credential. -
Stamp the namespace on each pipeline. On each listener's pipeline add an Add Fields processor with the Upsert action on
chronicle_namespace, set to that tenant's slug. Upsert force-overwrites any value the edge may have supplied, and because it does not touchlog_typeit is safe on a listener carrying many log types. Leavelog_typetagging to the edge collector. -
Hold the credential once, on the gateway. Add a single Google SecOps destination carrying the ingestion credential (WIF where you can) and route every listener's pipeline to it. This is the credential-isolation win: the long-lived secret never leaves your zone.
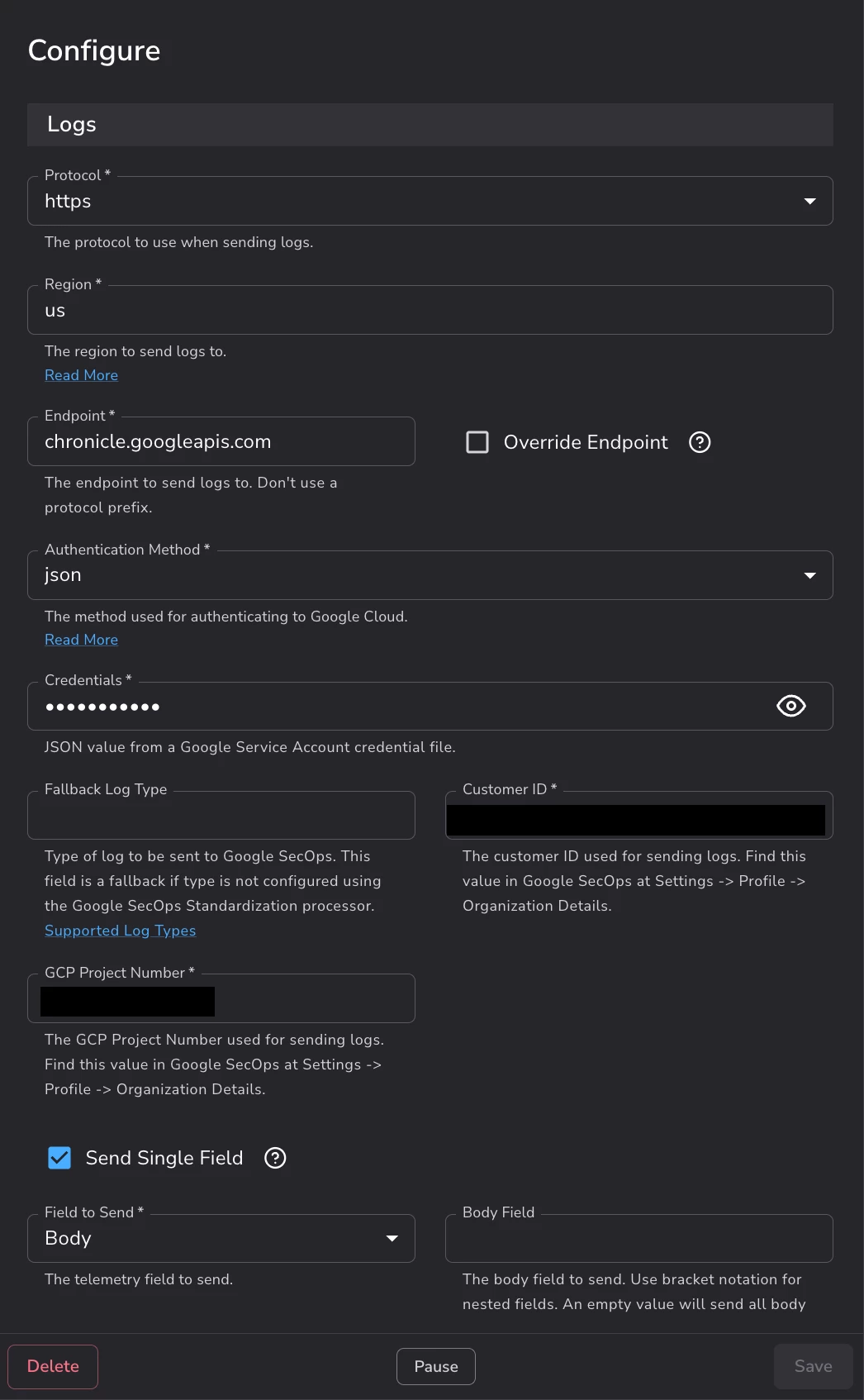
Figure 10 — The gateway's Google SecOps destination: region us, endpoint chronicle.googleapis.com, and Authentication Method set to json (key-based). Customer ID and GCP Project Number are redacted here; switching Authentication Method to WIF (by setting the Authentication Method set to auto) removes the long-lived credential this form otherwise requires. -
Lock each door. A port identifies but does not authenticate, so put an authenticator on each listener. You can use a firewall allowing only the tenant's static source IP for a particular gateway endpoint (IP and port pair), add a Routing Connector with a condition that checks the traffic for a token sent within the telemetry data, or leverage mTLS when you need a certificate-based identity.
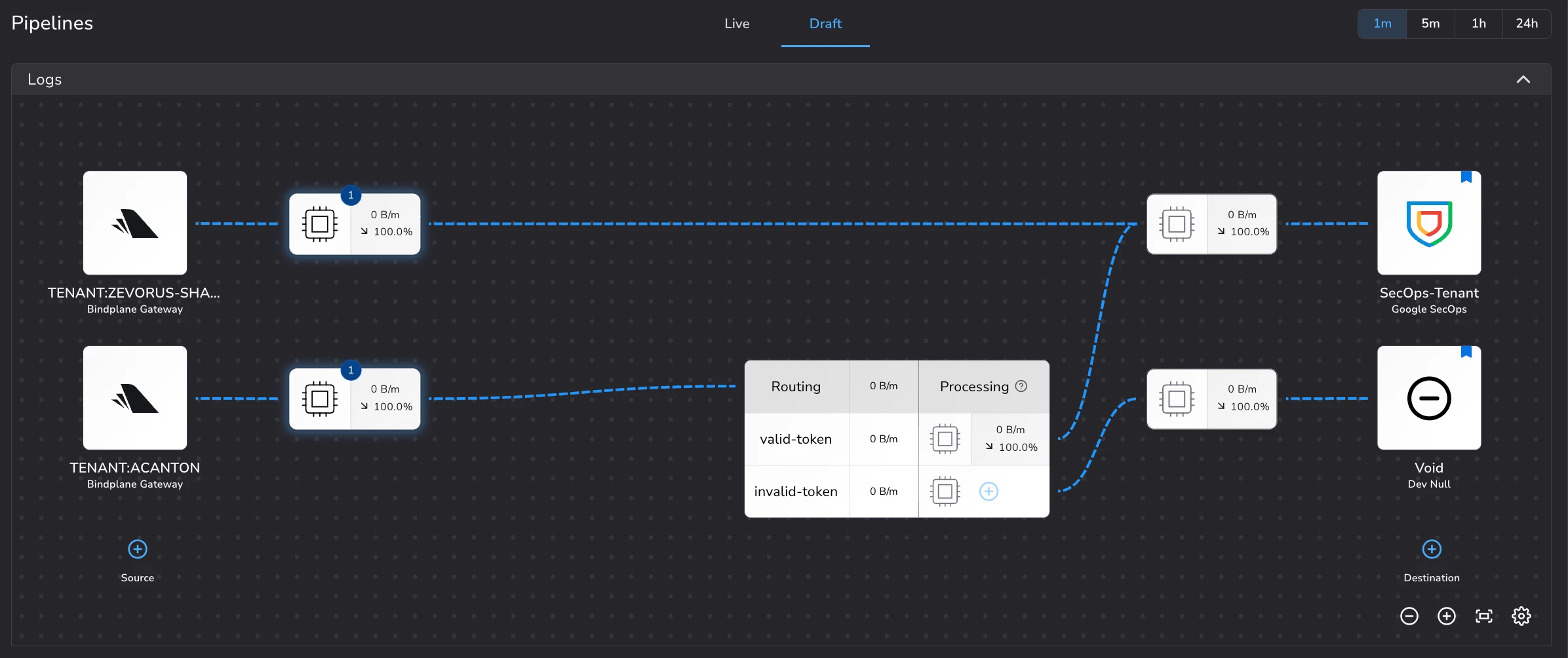
Figure 11 — A Routing processor in front of the gateway's destinations: telemetry carrying a valid-token continues to the SecOps-Tenant destination, and anything else (invalid-token) is dropped at the Void Dev Null destination rather than reaching Google SecOps. -
Plan for availability before the second tenant. A shared gateway is a single point of failure, so once a second tenant depends on it (like in this example), run two or more gateway replicas behind a load balancer (see the references).
-
Validate per tenant. In Google SecOps UDM Search, filter
metadata.base_labels.namespaces = "slug"over the last minutes and confirm the tenant's events arrive, parsed and carrying only their own namespace. You can repeat for each slug, or run the following aggregation to list them all in one table:metadata.base_labels.namespaces != ""
match:
metadata.base_labels.namespaces
outcome:
$event_count = count_distinct(metadata.id)
order:
$event_count descEach row is a namespace and its event count over the window, so a correctly wired tenant appears the moment it starts ingesting, and a slug that never shows up is your cue to recheck that tenant's edge and listener.
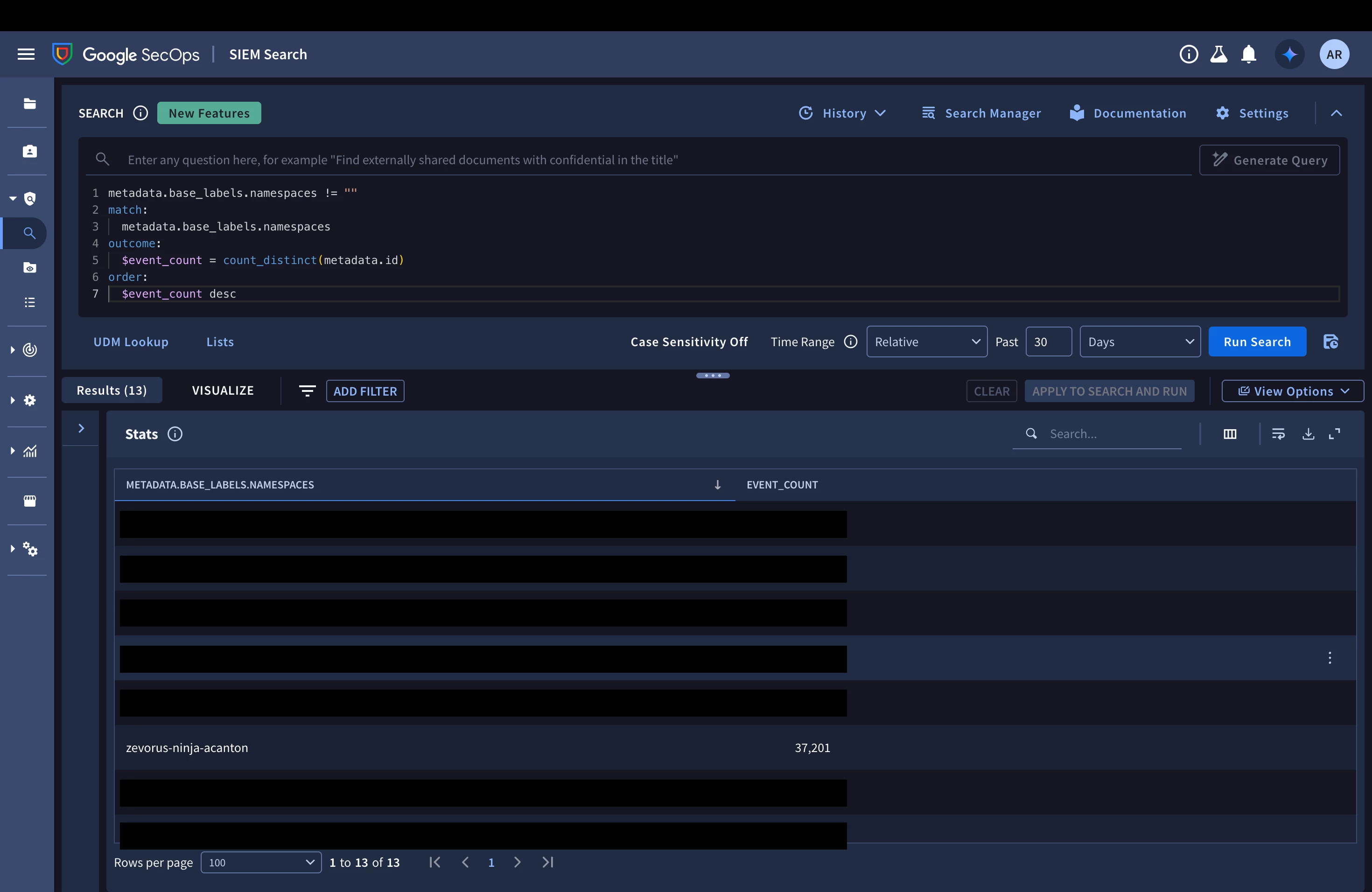
Figure 12 — The validation query run in Google SecOps UDM Search: each row is a namespace and its event count over the window. zevorus-ninja-acanton shows 37,201 events, confirming its listener is wired correctly; other tenants' rows are redacted here.
Note: The exact field names and screens vary slightly across Bindplane versions; treat the steps above as the architecture to reproduce, not a click-by-click script.
What's next
The telemetry is in and correctly tagged, and the wire it crossed is protected. That is the first plane done. Part 3 takes up the other two: making sure each analyst sees only their own tenant (the Data RBAC scope) and each alert lands in the right queue (the SOAR environment), both keyed off the same slug you have been stamping all along. That is where the one-string discipline from Part 1 finally pays off across all three planes, and where we look closely at the one enforcement detail that surprises people: a scope does not match by prefix.
References
- Part 1 of this series — Multi-tenancy on a single Google SecOps: the isolation challenge.
- Google SecOps — ingestion methods and deploying the Bindplane agent.
- Bindplane — high availability and the load balancer it requires (the HA build itself is out of scope here).
- Community — Adoption Guide: Getting Started with Bindplane.